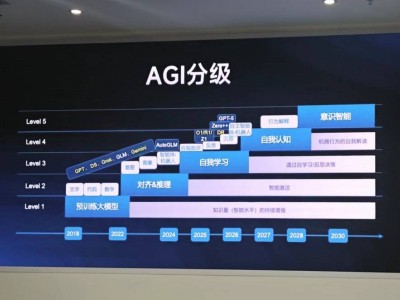
摘要:4比1获胜。这是人工智能与人类比拼棋力的最终战报。由谷歌旗下DeepMind公司研发的机器程序AlphaGO以大比分战胜了职业围棋九段选手李世石,继1997年IBM“深蓝”击败卡斯帕洛夫之后,人工智能取得的又一次颇具里程碑意义的胜利。但不止是围棋,人工智能其实早已实实在在的参与到我们的日常生活,每天打开手机看到的跟我们相关的广告,其中背后的移动DSP广告投放技术就是目前人工智能商用的最前沿领域之一。
人工智能科学家们一直以来对攻克棋类游戏十分着迷。从跳棋到国际象棋,他们不断证明计算机程序,或者说人工智能已经比任何一个人类棋手都要优秀。但围棋却是唯一没有被计算机攻克的棋类,被称作棋类游戏“最后的王冠”。
“深思”的AlphaGO

人们对于棋类游戏的破解从蛮力开始,计算机可以凭借远超人类的计算能力,推出在任何一种局面下的最优解。例如跳棋的可能性约为10的20次方,计算机可以枚举出所有走法;国际象棋大约为10的47次方,此时机器的计算能力开始捉襟见肘,好在科学家们有了新办法:程序可以在所有走棋的选项中,找出几个最佳解,然后将计算能力放在所选的几步棋产生的后续变化上。
计算机程序之所以可以这么做,是因为国际象棋有着较多的约束性规则和价值判断结构,比如马要走日字型,其杀伤力大于兵,而皇后可沿随意直行,价值更在二者之上。
相比之下,围棋的难点在于规则简单却变化惊人,它可产生的棋局达10的170次方,远超宇宙中所有原子的数量,而仅仅是黑白两子却又孕育出多变的战术,一步棋的价值,往往随着接下来的落子不同而不同。这些都不是由规则本身所约束形成的。
那么,如何让计算机程序像人类一样对弈?
AlphaGO使用了三个技术来实现:蒙特卡洛树搜索作为主架构、强化学习作为训练方法、深度的神经网络是学习工具。(这里不详细展开叙述,有兴趣的读者可以自行了解。)
AlphaGO相比之前围棋算法的突破在于使用了Deep Learning深度学习和一个高效的快速减枝算法,从过去的人教机器的策略变成机器自我学习。Deep learning起源于图像识别(类似于科幻电影中某安全局使用的天眼系统,利用摄像头全世界找人),而目前Deep learning在工业界使用最广领域之一是在线广告行业,在国内像BAT以及京东等平台的广告系统都在使用这门技术。
借助Deep Learning可以简单概括AlphaGO的工作原理:首先想要教机器程序学会下棋,得让他能自己理解围棋中蕴含的一般法则。为了做到这一点,AlphaGO需要大量的练习数据和处理数据的能力。
科学家们找了3000万份人类已知的棋谱,并让AlphaGO自己“左右互搏”,从而产生大量的样本数据。随后这些数据被灌注到AlphaGO的算法中,它由两个关键部分组成,决策网络(Policy Network)负责提炼围棋的特征、规则并总结经验,然后给出每一步的推荐走法;价值网络(Value Network)负责根据前者的推荐,来计算每步棋可能的获胜概率。由于围棋的可能性过大,所以价值网络通常只会审查几步之后的结果,选择最有可能赢得比赛的落子。
AlphaGO正是凭借科学家们在机器学习上的智慧,站到了与千年前发明围棋这项游戏的先贤们同样的高度,甚至更高。
AlphaGO本身是一个通用计算程序,意味着未来可以应用并拓展到更多的领域,而不只是下棋。事实上,人工智能早已进入了我们的生活中,在商业和学术上都有了广泛的应用。例如自动驾驶、人脸识别、翻译、图像分类,甚至于你每天上网时看到的广告,都有人工智能的身影在里面。
移动DSP中的人工智能

广告将是下一个因人工智能而变革的行业,目前最成熟的人工智能商业化应用就是在互联网及程序化广告行业,精准、高效的投放机制彻底改变了传统广告。相比人工智能,人的优劣势是短时间的记忆容量和准确度优先,而分类整理信息的速度有限。当需要处理的信息过于庞大、规则复杂、但目标清晰、可量化计算时,人工智能就有了发挥的空间。
DSP是汇聚了大量互联网流量的需求方广告平台,广告主的目标一直以来就很明确:把广告传达给自己目标用户。因为互联网本身数字化的特性,大量的数据将会被记录下来,比如IP&cookie,浏览的网页内容、时间,购买的商品等。这些都是广告投放时,来判断是否适合投放的主要依据和元数据。
而在移动互联网时代,无线二字将计算的维度进一步提升,同时信息脉络也更清楚。
首先,信息量成几何增长,移动设备可以揭示更多的数据,例如GPS位置信息、移动设备信息等,又因为使用方便,人们的日常生活如社交、出行、吃饭、旅游都会使用到手机,从而产生大量数据。
其次,移动端的数据信息链接的更为紧密,相比以往PC时代的IP和Cookie,移动设备号的唯一性可以更好的把相关信息串联起来,让分散的信息回归到一个人上。
在合法且安全保密的情况下,通过对这些信息的处理,移动DSP能筛选出最合适的流量投放广告,提高广告的效果。人工智能可以像下围棋一样,从海量数据中划分出对产品最感兴趣的用户,然后对每个消费者点击广告的概率进行预测,再加上DSP的实时竞价交易模式,考虑到钱的因素后,清晰的衡量投放效果的好坏,得出一个理想的eCPM。整个过程都有人工智能的参与,它在不断的学习中优化自己的投放功力。
同时, DSP的竞价环境更为复杂,因为需要预判其他的竞价者会如何出价,是否能够获得流量,加上动态变化的外部环境,像围棋一样,每一个选择都有着无穷无尽的变化。人工智能的运用使得DSP超越了传统的根据广告的特性挑选流量-投放-分析-再挑选流量投放的人工运营方式。
这一点在移动互联网时代尤为凸显,信息量的几何数增长+信息维度越来越多,人工操作遇到瓶颈,再深入下去会投入巨大人力和管理成本,选择移动DSP作为广告投放的助手可谓顺理成章。
确实目前的人工智能也有瓶颈,也有不如人的地方,比如对一些太复杂的局面做宏观的判断时会偶有失误,需要人为的从中进行优化干预。人工智能也像围棋一样,世界顶尖的高手凤毛麟角,好的人工智能优化师也是屈指可数。但人工智能可以复用,这将大大提高DSP的平均优化水平。
商业化代表作:OCPC
越来越多的移动广告平台开始研发人工智能来辅助甚至替代运营人员:即用机器代替运营人员投放广告,比如Facebook的OCPM和多盟的OCPC系统。
Facebook的OCPM系统即Optimized CPM。广告主在推广一个APP时,填写期望的APP单激活用户成本和整体的预算,广告系统会参考设定的成本智能的帮助广告主去出价,国内由于环境不同,DSP的结算一般按CPC的方式,并且广告主对成本的要求也会更严格,多盟在OCPM的基础上,结合中国移动DSP的流量特征和行业规则,开发出自主的智能投放引擎OCPC
所谓OCPC即智能出价的CPC,系统会像AlphaGO一样,借助多盟DMP,首先对每一个流量进行标签分类,然后针对不同广告主对流量的价值进行评估,依照结果系统会智能的给出合理的价格,并根据不同的流量情况,调整广告的创意组合。

广告主一直希望广告投放的效果成本可量化并且可实时反馈,比如一个游戏用户的获取成本或后续付费,一个电商用户的消费金额等等。以手机游戏广告为例,广告主期望在一定的用户获取成本内,投放量越多越好,以达到最大的用户触及,获得转化。
因此,人工智能投放系统OCPC可以针对每一个广告投放模拟一个独立的运营人员来实施,这个虚拟的“人”会关注多维度的、实时反馈的、历史积累的海量数据,针对该广告的特点、目标和实时反馈的投放效果,进行快速的计算和调整,得出最佳一步“棋”。
例如在游戏广告投放时,每一次请求过来,人工智能都能清晰知道以下信息:此次请求相关用户和所在场景的特征;用户历史上点击和下载其他游戏,甚至是付费的情况;当前DSP内整个广告库其他广告的情况,以及外部竞争环境。然后,根据以上信息和规则,针对当前游戏广告的成本目标和已投放的结果,给出一个相对最优的出价。
人工智能,未来可期
人们的生活越来越信息化,人工智能的发挥空间也就越大,一些科幻电影里的场景也不会太遥远,比如当你走在大街上不小心划破了手,这时旁边的公交车站上的一块电子广告屏会向你展示一条创口贴的广告,并给你递上产品。
人工智能发展的障碍在于如何获得人类的信任:大多数普通人对于人工智能还不太了解,电影等文艺作品中的剧情,放大了人们对于未知事物的恐惧和拒绝心理。然而事实上,人工智能的可控性和可预见性都要比人类自己高出很多。
Facebook的OCPM和多盟OCPC也一样,不仅是广告主,还有平台运营人员都对其存在一定程度的质疑。比如一开始成本很高,点击单价出的很大时,确实会犹豫是不是人工智能出了问题,但对人工智能多些信任,往往会使得结果往更好的方向发展。据悉,多盟OCPC系统从最开始不到5%的使用率,经过一年多的成长,到现在已有90%的使用率,都代表了信任是可以用时间和正向的结果来推进的。
另一个人工智能需要面临的挑战是计算能力的极限。最完美的情况是,每天上百亿的广告请求,人工智能可以针对每个广告给出上百亿次独立的最优出价,然而由于机器性能等原因,目前DSP的人工智能还达不到这种水平。但对流量的划分已经能达到上百万份,即一个广告给出上百万个有针对性的智能出价,并进行跟踪分析修正出价,这远超出人工运营的上限,并且随着科技的发展,效果仍在提升。
DeepMind创始人之一哈萨比斯认为虽然AlphaGO的深度学习效果十分惊人,已经可以通过算法洞察一件事物的内在规则,但人工智能仍是计算机程序,还未达到真正“智”的阶段——像人类一样思考,并把知识转化为工具。AlphaGO还做不到把围棋上的经验,应用到其他领域上,它与我们常用的Excel等计算机程序并无本质差别。
不过他也认为,人工智能的未来是值得期待的,因为它在不断的学习,会越来越强大,“如果问我人工智能是否有极限?目前我们还没发现它。”