相比于一年举办数十场的各种类型的图像识别/分割大赛而言,强化学习的顶级赛事可谓是寥寥可数,其技术报告更是凤毛麟角。强化学习在赛事领域到底有哪些常用的解题思路以及黑科技呢?今天我们通过解读NeurIPS强化学习赛事颁奖现场的技术报告,为大家带来仿生人控制大赛这一国际顶尖赛事的冠军解决方案。
训练代码的开源路径:https://github.com/PaddlePaddle/PARL
在12月8日-14日于加拿大温哥华举办的机器学习领域顶级会议NeurIPS 2019上,百度连续第二年拿下强化学习赛事冠军。而在颁奖典礼现场,百度技术团队分享了此次能够获得冠军的关键3点:高性能的并行框架PARL、课程学习机制以及提升模型鲁棒性的新算法。

据悉,斯坦福大学仿生动力学实验室连续三年在NeurIPS上举办了关于仿生人的控制竞赛---通过肌肉来控制仿生人来灵活运动,目标是将强化学习这项潜力巨大的技术应用到人体肌肉运动研究领域中,进一步理解对人体腿部的运动原理,为该领域研究拓展全新的研究思路。
今年赛事的任务是通过强化学习训练一个模型来控制仿生人进行灵活运动,使得其可以朝着任意角度行走,并可以实时调整速度快慢。这一目标相比去年阶段性地变化行走目标而言,主要变化在实时变换速度,任意行走角度上,给今年的参赛选手带来了极大的挑战(赛事结果报导见上一篇文章)。
如下为百度技术团队在颁奖典礼上的技术报告:
PARL:最高可支持20000个计算节点并发计算的强化学习框架
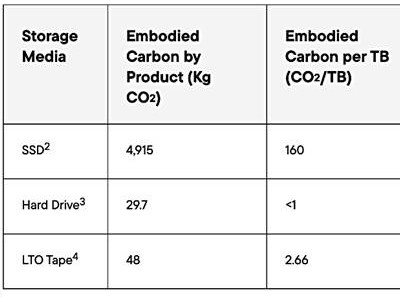
历届赛事采用的是斯坦福实验室设计的opensim仿生人模型,这一仿真器基于生物动力学原理,尽可能地还原了真实的物理情况。但是高仿真度意味需要耗费更多的计算资源,这使得它的运行速度相比主流强化学习仿真环境慢很多,平均速率只有4帧/秒(主流环境Mujoco最高可达到1000帧/秒)。要解决这个问题,最直接了当的方法是利用多个CPU进行并行计算,同时进行仿真。目前开源社区中已经有一部分RL框架支持并行计算,比如最为流行的baseline(OPENAI开源),但是这类框架的并行计算是基于mpi4py通讯协议实现的。用户不仅需要熟悉mpi的常用接口,还得用特定的命令才能启动多机训练,相对于单机版本的改动极大,用户上手成本很高。

而在飞桨PARL框架下,并行计算代码编写几乎没有额外学习成本。PARL鼓励用户写传统的python多线程代码来达到并行目的,开发者并不需要关注网络传输的实现,只要增加一个并行修饰符就可以实现并行化(尽管python多线程受全局锁GIL限制而不能实现真正的并行,但是这个修饰符的底层实现是独立进程级别的,不受这一限制)。获胜团队实现了并行版本的DDPG/PPO算法,使用了上百个仿真环境在CPU集群上进行仿真,探索不同的状态空间,并且通过网络传输把数据收集到训练机器上通过GPU预测以及训练(见图1),将原先单CPU需要5小时迭代一轮的单机PPO算法时间压缩到了不到1分钟。

图1
课程学习机制
本次比赛的一个重要挑战是在高达117维度的连续空间上训练一个可以灵活行走的模型,搜索空间极大,模型在训练的过程中很容易陷入局部最优,例如图2这种螃蟹一样横着走的情况。

图2
如何才能避免这种情况,让模型学习到一个灵活的走路姿势,和普通人行走一样正常呢?
在参赛过程中,该团队注意到把强化学习的学习目标直接设定为低速向前的话,模型会“抖机灵”地探索到各种各样奇怪的姿势来达到低速行走的目标,比如拖着腿走,小步跳着走,甚至横着走。这些奇怪的姿势导致模型陷入局部最优,短期内虽然拿到了不错打分,但效果却无法进一步提升。如何学习到更接近于人类的稳定姿态?参赛团队进一步发现,把目标设定为向前奔跑且跑得越快越好,模型学出来的姿势较自然。仿真环境中的仿生人先迈出右腿,身体向前倾斜,然后向前冲刺,最后和普通人一样向前跑起来(见图3)!该团队认为出现该情况的原因在于此:低速行走有非常多的姿势能够实现,也很容易陷入局部最优;但是目标设定为最快速度奔跑的时候,模型的可能选择反倒更少了----像人类一样冲刺。在学会了向前奔跑之后,参赛选手再逐步把目标速度降低,让模型保持原先的姿势的同时,逐步学会低速行走。有了这种“课程”式的训练过程,模型可以学习到真正与人类一样的行走姿势,这也为后续的灵活变换方向奠定了基础。

图3
RAVE:提升鲁棒性的新算法
RAVE的全称是Risk-averse Value Expansion,是该团队提出的基于模型的强化学习算法(model-based RL),这个算法在本次夺冠过程中起到了极为关键的作用,最终也获得了赛事的Best Machine Learning Paper荣誉。这次赛事的最为重要的一个挑战是仿生人需要实时变换速度,reward是取决于仿生人的实时速度与指定速度之间的差值,但是未来的目标速度是无法提前得知的(赛事规则限制)。这一个问题给强化学习的学习机制带来了很大的干扰:由于未来的目标速度无法预估,会使得在当前状态下,模型错误地估计了未来风险,从而采取一些风险偏高的行为而很容易摔倒。针对这一个问题,PARL团队从对环境的建模入手,在借鉴了发表在18年NeurIPS的Ensemble of Probabilistic Models(PE)工作后,他们采用了多个高斯模型对环境进行建模,同时捕捉建模的误差以及环境的随机性,并通过取多个预估值的置信度下界的方式,来解决值函数在计算过程中过于“乐观”的情况。凭借着这个算法,百度参赛团队最终训练出了图4这样灵活的控制模型,连续两年拿下该赛事的冠军名次。

图4
最后参赛团队表示已经把相关训练代码开源到PARL仓库中,方便大家了解强化学习竞赛的训练流程,具体可以参阅如下路径(https://github.com/PaddlePaddle/PARL/tree/develop/examples/NeurIPS2019-Learn-to-Move-Challenge)。