
在美国硅谷圣何塞召开的 NVIDIA GTC 大会上,全球领先的向量数据库公司 Zilliz 发布了 Milvus 2.4 版本。这是一款革命性的向量数据库系统,在业界首屈一指,它首次采用了英伟达 GPU 的高效并行处理能力和 RAPIDS cuVS 库中新推出的 CAGRA( CUDA-Accelerated Graph Index for Vector Retrieval )技术,提供基于GPU的向量索引和搜索加速能力,性能可提升 50 倍。
Milvus 2.4 的 GPU 加速性能提升效果令人惊叹。基准测试显示,与目前市面上最先进的基于 CPU 处理器的索引技术相比,新版 GPU 加速 Milvus 能提供高达 50 倍的向量搜索性能提升。目前,Milvus 2.4的开源版本已经对外发布。
对于希望使用全托管云数据库服务的企业用户来说,还有一个好消息,那就是 Zilliz 提供的 Milvus 商业版全托管云服务 Zilliz Cloud 计划将在今年晚些时候升级推出 GPU 加速功能。
▲Zilliz Cloud
截至当前,Zilliz Cloud 已经实现包括阿里云、腾讯云、AWS、谷歌云和微软云在内的全球 5 大云 13 个节点的全覆盖,除了分布在杭州、北京、深圳的 5 个国内服务区,其他 8 个节点分布在海外,包括美国的弗吉尼亚州、俄勒冈州、德国的法兰克福、新加坡等城市和地区。Zilliz 已成为首家同时提供海内外多云服务的向量数据库企业。
Milvus 是什么?
Milvus 是一款为大规模向量相似度搜索和 AI 应用开发设计的开源向量数据库系统。它最初由 Zilliz 公司发起开发,并在 2019 年开源。2020年,该项目加入 Linux 基金会并成功毕业。
自推出以来,Milvus 在 AI 开发者社区中大受欢迎并被广泛采用。在GitHub上,Milvus 拥有超过26,000个星标和 260 多位贡献者,全球下载和安装量超过 2000 万次,已经成为全球使用最广泛的向量数据库之一。Milvus 已经被 5,000 多家企业所采用,服务于AIGC、电子商务、媒体、金融、电信和医疗等多个行业。

▲部分 Milvus 企业用户列表 来源:Milvus官网
为什么需要 GPU 加速?
在数据驱动的时代背景下,快速准确地检索大量非结构化数据对于支持前沿AI应用至关重要。无论是生成式AI、相似性搜索,还是推荐引擎、虚拟药物发现,向量数据库都已成为这些高级应用的核心技术。然而,对于实时索引和高吞吐量的需求不断挑战着基于CPU的传统解决方案。
实时索引
向量数据库通常需要持续且高速地摄取和索引新的向量数据。实时索引的能力对于保持数据库与最新数据的同步至关重要,避免产生瓶颈或积压。
高吞吐量
许多使用向量数据库的应用程序,例如推荐系统、语义搜索引擎和异常检测等,都需要实时或近实时的查询处理。高吞吐量确保向量数据库能够同时处理大量涌入的查询,为最终用户提供高性能的服务。
向量数据库的核心运算包括相似度计算和矩阵运算,这些运算具有并行性高和计算密集等特点。GPU 凭借其成千上万的运算核心和强大的并行处理能力,成为了加速这些运算的理想选择。
Milvus 2.4 技术架构
为了应对这些挑战,英伟达开发了CAGRA。这是一个利用GPU的高性能能力为向量数据库工作负载提供高吞吐量的GPU加速框架。接下来,我们来看看 CAGRA 是如何与 Milvus 系统整合的。
Milvus 专为云原生环境设计,采用模块化设计理念,将系统分为多个组件,分别处理客户端请求、数据处理以及向量数据的存储和检索。得益于这种模块化设计,Milvus 可以轻松地更新或升级特定模块,而无需改变模块间的接口,使得在 Milvus 中集成 GPU 加速变得简单可行。

▲Milvus 2.4 架构图
Milvus 2.4 的架构包括协调器、访问层、消息队列、工作节点和存储层等组件。工作节点进一步细分为数据节点、查询节点和索引节点。其中,索引节点负责构建索引,查询节点负责执行查询。
为了充分利用GPU的加速能力,CAGRA 被集成到了 Milvus 的索引节点和查询节点中。这种集成使得计算密集型任务,如索引构建和查询处理,能够被转移到 GPU 上执行,从而利用其并行处理能力。
在 Milvus 的索引节点中,CAGRA 被集成到了索引构建算法中,利用 GPU 硬件来高效地构建和管理高维向量索引,显著减少了索引大规模向量数据集所需的时间和资源。
同样,在 Milvus 的查询节点中,CAGRA 被用于加速执行复杂的向量相似度查询。借助GPU的处理能力,Milvus 能够以前所未有的速度执行高维距离计算和相似性搜索,从而加快查询响应时间并提升整体吞吐量。
性能评测结果
在性能评估过程中,我们使用了 AWS 上的三种公开实例类型:
m6id.2xlarge:搭载Intel Xeon 8375C 处理器的 CPU 实例
g4dn.2xlarge:配备NVIDIA T4 处理的GPU加速实例
g5.2xlarge:配备NVIDIA A10G 处理器的GPU加速实例
我们通过这些不同的实例类型来评估 Milvus 2.4 在不同硬件配置下的性能和效率,其中m6id.2xlarge 作为基于 CPU 处理器的性能基准,而 g4dn.2xlarge 和 g5.2xlarge 则用来评估GPU 加速的优势。

▲基于 AWS 的评测环境
在评测中,我们选用了 VectorDBBench([4]) 的两个公开向量数据集,评估 Milvus 在不同数据量和向量维度下的性能和可扩展性:
OpenAI-500K-1536-dim:包含50万个1,536维的向量,由 OpenAI 语言模型生成
Cohere-1M-768-dim:包含100万个768维的向量,由Cohere语言模型生成
索引构建时间
在索引构建时间的评测中,我们发现对于 Cohere-1M-768-dim 数据集,使用 CPU( HNSW )的索引构建时间为 454 秒,而使用 T4 GPU( CAGRA )仅为66秒,A10G GPU( CAGRA )更是缩短到了 42 秒。对于 OpenAI-500K-1536-dim 数据集,CPU( HNSW )的索引构建时间为359秒,T4 GPU( CAGRA )为45秒,A10G GPU(CAGRA)则为22 秒。
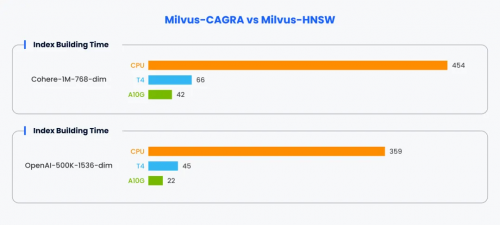
▲评测索引构建时间
这些结果清楚地表明,GPU 加速框架 CAGRA 在索引构建方面明显优于基于 CPU 的 HNSW,其中 A10G GPU 在两个数据集上都是最快的。与 CPU 实现相比,CAGRA 提供的 GPU 加速将索引构建时间缩短了一个数量级,展示了利用 GPU 并行性进行计算密集型向量运算的优势。
吞吐量
在吞吐量方面,我们比较了集成 CAGRA GPU 加速的 Milvus 与使用 CPU 上 HNSW 索引的标准 Milvus 实现。评估指标是每秒查询数( QPS ),用于衡量查询执行的吞吐量。在向量数据库的不同应用场景中,查询的批量大小( 单条查询处理的查询数量 )往往不同。在测试过程中,我们采用了1、10 和 100 这三种不同的批量大小,获取真实而全面的评测结果数据。
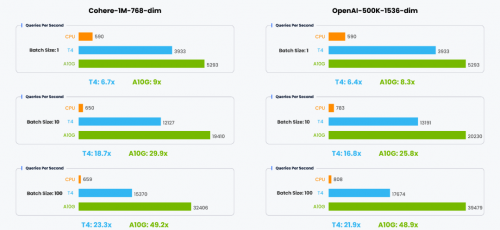
▲评测吞吐量
从评估结果来看,对于批量大小为 1 的情况,T4 GPU 比 CPU 快 6.4 到 6.7 倍,A10G GPU 则快 8.3 到 9 倍。当批量大小增加到 10 时,性能提升更加显著:T4 GPU 快 16.8 到18.7倍,A10G GPU 快25.8 到 29.9 倍。当批量大小为 100 时,性能提升持续增长:T4 GPU 快 21.9 到 23.3 倍,A10G GPU 快 48.9 到 49.2 倍。
这些结果表明,利用 GPU 加速向量数据库查询可以获得巨大的性能提升,尤其是对于更大的批量大小和更高维度的数据。集成 CAGRA 的 Milvus 释放了 GPU 的并行处理能力,实现了显著的吞吐量改进,非常适合要求极致性能的关键场景下的向量数据库工作负载。
开启新纪元
将英伟达 CAGRA GPU 加速框架集成到 Milvus 2.4 中,标志着向量数据库领域的一项重大突破。通过利用 GPU 的大规模并行计算能力,Milvus 在向量索引和搜索操作方面实现了前所未有的性能水平,开启了实时、高吞吐量向量数据处理的新时代。
5年前, Zilliz 的工程师们在上海漕河泾的厂房里敲下了向量数据库历史上的全球第一行代码,开启了研发面向非结构化数据管理的新一代数据库的探险。
今天,Zilliz 和英伟达合作推出 Milvus 2.4,展现了开放创新和社区驱动发展的力量,为向量数据库带来了 GPU 加速的新纪元。这一里程碑事件预示着又一个技术变革的来临,向量数据库有望经历类似于英伟达在过去 8 年中将 GPU 算力提高 1000 倍的指数级性能飞跃。
在未来十年,我们将见证向量数据库性能的 1000 倍飞跃。这将引发一场数据处理方式的范式转变,重新定义我们处理和利用非结构化数据的能力。
Zilliz 最新动态
除了发布业界超前的 Milvus 2.4,Zilliz 近期还有不少新动作:
Zilliz 正式开启 AI 初创计划!Zilliz AI 初创计划是面向 AI 初创企业推出的一项扶持计划,预计提供总计 1000 万元的 Zilliz Cloud 抵扣金,致力于帮助 AI 开发者构建高效的非结构化数据管理系统,助力打造高质量 AI 服务与运用,加速产业落地。Zilliz 将为全球的 AI 初创团队提供资源、技术、市场推广、销售等全方位的支持,符合要求的团队可获得独家资源与支持。欢迎各位开发者登陆 Zilliz 中文官网首页了解 Zilliz AI 初创计划,与 Zilliz 一起共建 AI 生态!
Zilliz Cloud 正式登录腾讯云,覆盖北京、上海两区,进一步为海内外用户提供更丰富的多云支持的向量数据库服务。截至目前,Zilliz Cloud 已实现全球 5 大云 13 个节点的全覆盖,除了在中国的杭州、北京、深圳五大服务区,其他 8 个节点分布在海外,包括美国的弗吉尼亚州、俄勒冈州、德国的法兰克福、新加坡等城市和地区。至此,Zilliz 已成为全球首个提供海内外多云服务的向量数据库企业。
Zilliz 发布 「Milvus 北极星计划」,旨在汇集和团结 Milvus 社区的热心用户及开发者,组成社区大使团队。根据不同角色擅长的能力(Coding、写作、沟通、布道、活动组织等),在社区中分配职责,共同建设运营 Milvus 社区,为社区发展壮大探索方向、添砖加瓦。最终将 Milvus 社区打造为一个充满活力、创新开放、团结互助的全球化社区。关注 Zilliz 微信公众号,回复“北极星”可了解详情。















