昨日,深度求索公司宣布其DeepSeek R1模型已完成最新的小版本迭代,新版本被命名为DeepSeek-R1-0528。用户现在可以通过官方网站、App以及小程序进入对话界面,并启用“深度思考”功能,来体验这一最新版本。同时,API接口也已同步更新,且调用方式维持原样。
深度求索公司在晚间详细公布了此次DeepSeek-R1-0528版本的更新内容。据悉,该版本依旧基于2024年12月发布的DeepSeek V3 Base模型,但后训练过程中投入了更多的算力,显著提升了模型的思维深度和推理能力。在多个基准测评中,包括数学、编程和通用逻辑等方面,DeepSeek-R1-0528取得了国内领先的成绩,并且在整体表现上已接近国际顶尖模型,如o3和Gemini-2.5-Pro。
在各项评测集上,DeepSeek-R1-0528均展现出卓越表现。特别是在AIME 2025测试中,新模型的准确率从旧版的70%提升到了87.5%。这一显著进步得益于模型在推理过程中思维深度的增强。在AIME 2025测试集上,旧版模型平均每题使用12K tokens,而新版模型则提升至23K tokens,显示出更为详尽和深入的解题思考。
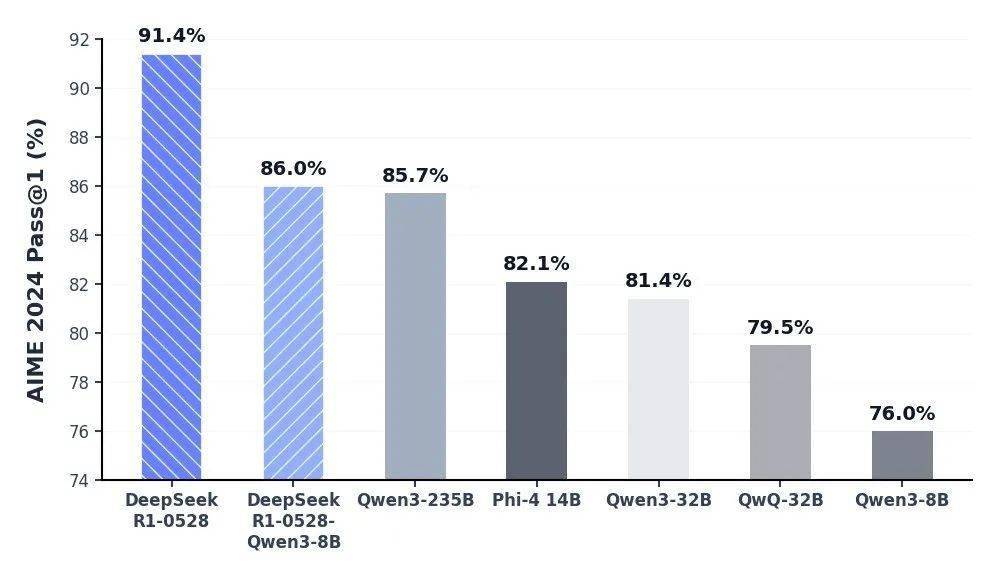
官方还利用DeepSeek-R1-0528的思维链对Qwen3-8B Base进行了蒸馏,得到了DeepSeek-R1-0528-Qwen3-8B。在数学测试AIME 2024中,该8B模型的表现仅次于DeepSeek-R1-0528,超越了Qwen3-8B(+10.0%),与Qwen3-235B相当。深度求索公司认为,DeepSeek-R1-0528的思维链将对学术界推理模型的研究以及工业界小模型的开发产生重要影响。
除了深度思考能力的增强,DeepSeek-R1-0528还在其他方面进行了优化。针对“幻觉”问题,新版模型在改写润色、总结摘要、阅读理解等场景中,幻觉率降低了45%至50%左右,提供了更为准确和可靠的结果。在创意写作方面,新版R1模型针对议论文、小说、散文等文体进行了优化,能够输出篇幅更长、结构内容更完整的长篇作品,并且写作风格更加贴近人类偏好。
在工具调用方面,DeepSeek-R1-0528也进行了支持,不过目前还不支持在“思考”功能中进行工具调用。当前,该模型在Tau-Bench测评中的成绩为airline 53.5% / retail 63.9%,与OpenAI的o1-high相当,但与o3-High以及Claude 4 Sonnet仍有一定差距。
DeepSeek-R1-0528还在前端代码生成、角色扮演等领域的能力上进行了更新和提升。用户现在可以在网页端调用该模型,使用HTML/CSS/Java开发各种应用。

API接口也同步进行了更新,调用方式保持不变。新版R1 API支持查看模型的思考过程,并增加了Function Calling和JsonOutput的支持。不过,官方对max_tokens参数的含义进行了调整,现在该参数用于限制模型单次输出的总长度(包括思考过程),默认为32K,最大为64K。API用户需及时调整该参数,以防输出被提前截断。
此次更新后,官方网站、小程序、App端和API中的模型上下文长度仍为64K。若用户对更长的上下文长度有需求,可以通过第三方平台调用上下文长度为128K的开源版本R1-0528模型。
DeepSeek-R1-0528与之前的DeepSeek-R1使用同样的base模型,仅改进了后训练方法。私有化部署时,用户只需更新checkpoint和tokenizer_config.json(tool calls相关变动)。该模型参数为685B(其中14B为MTP层),开源版本上下文长度为128K(网页端、App和API提供64K上下文)。用户可以在Huggingface等平台下载DeepSeek-R1-0528的模型权重,此次开源仓库(包括模型权重)仍然采用MIT License,并允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。