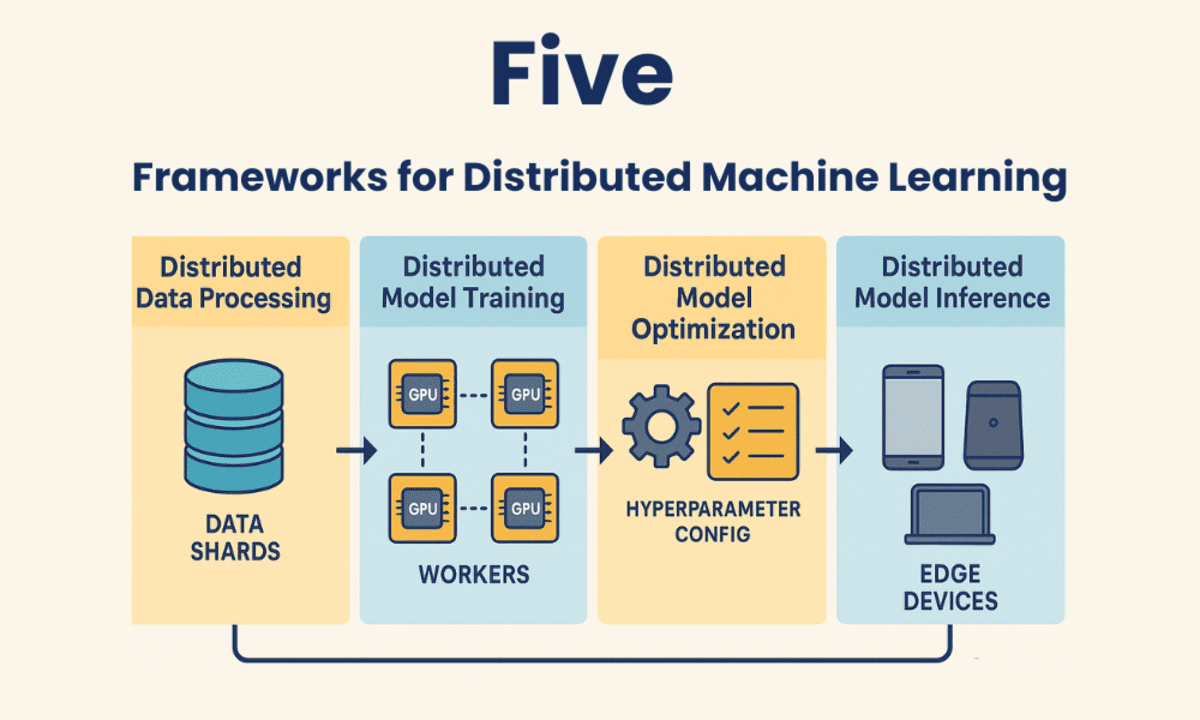
在机器学习和人工智能领域,分布式计算框架正成为优化资源、加速工作流程和降低成本的关键工具。这些框架允许开发者跨多台机器(无论是CPU、GPU还是TPU)进行模型训练,从而显著缩短训练时间,并有效处理大型复杂数据集。
在众多分布式机器学习框架中,PyTorch Distributed以其动态计算图、易用性和模块化设计赢得了广泛认可。PyTorch Distributed通过其分布式数据并行(DDP)功能,实现了高效的数据分割和梯度同步,支持跨多个GPU或节点的模型训练。PyTorch Distributed还支持TorchElastic,实现了动态资源分配和容错训练,使其在各种规模的集群上都能表现出色。对于已经在使用PyTorch进行模型开发的团队来说,PyTorch Distributed无疑是一个增强工作流程的理想选择。
另一个备受瞩目的框架是TensorFlow Distributed,它是TensorFlow为分布式训练提供的强大支持。TensorFlow Distributed通过tf.distribute.Strategy提供了多种分布式策略,如MirroredStrategy用于多GPU训练,MultiWorkerMirroredStrategy用于多节点训练,以及TPUStrategy用于基于TPU的训练。TensorFlow Distributed与TensorFlow生态系统无缝集成,包括TensorBoard、TensorFlow Hub和TensorFlow Serving,使其在大规模训练深度学习模型时成为首选。TensorFlow Distributed还得到了谷歌云、AWS和Azure等云服务提供商的大力支持,便于在云端运行分布式训练作业。
除了PyTorch Distributed和TensorFlow Distributed之外,Ray也是一种备受关注的分布式计算框架。Ray针对机器学习和AI工作负载进行了优化,提供了用于训练、调优和服务模型的专用库。Ray Train可以与PyTorch和TensorFlow等流行机器学习框架配合使用,实现分布式模型训练。Ray Tune则针对跨多个节点或GPU的分布式超参数调优进行了优化。Ray Serve还提供了用于生产机器学习管道的可扩展模型服务。Ray的动态扩展能力使其能够在小型和大型分布式计算中都保持高效。
对于处理大规模结构化或半结构化数据的场景,Apache Spark则是一个不可或缺的选择。Apache Spark是一种成熟的开源分布式计算框架,专注于大规模数据处理。其内置的MLlib库提供了机器学习算法的分布式实现,包括回归、聚类和分类等。Spark可以与Hadoop、Hive以及Amazon S3等云存储系统无缝集成,使其在处理PB级数据时依然高效。Spark的可扩展性使其能够扩展到数千个节点,满足大规模数据处理的需求。
对于希望扩展现有工作流程的Python开发者来说,Dask则是一个轻量级的选择。Dask扩展了Pandas、NumPy和Scikit-learn等流行Python库的功能,使其能够处理内存容纳不下的数据集。Dask可以并行化Python代码,并以极少的代码更改将其扩展到多个核心或节点。Dask还与Scikit-learn、XGBoost和TensorFlow等常用机器学习库无缝协作,使其在处理大型数据集时更加高效。
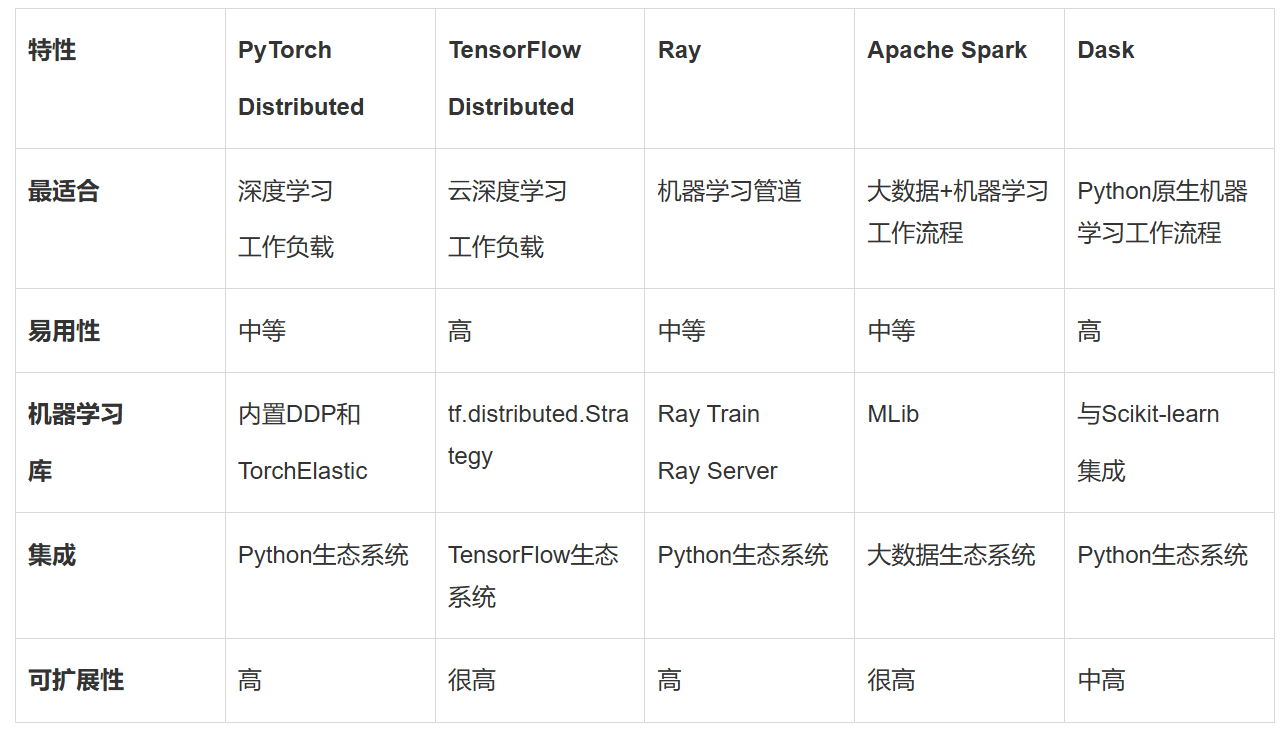
在实际应用中,选择哪个分布式机器学习框架取决于具体的需求和项目背景。PyTorch Distributed和TensorFlow Distributed最适合大规模深度学习工作负载,尤其是当团队已经在使用这些框架时。Ray则非常适合构建采用分布式计算的现代机器学习管道。Apache Spark则是大数据环境中分布式机器学习工作流程的首选解决方案。而对于希望高效扩展现有工作流程的Python开发者来说,Dask则是一个轻量级且易于上手的选择。