
在人工智能领域,大模型行业正掀起一股前所未有的“规模定律”热潮。各大科技巨头与研究机构不惜投入巨资,试图通过扩大数据规模来推动模型性能的飞跃。然而,这一看似直接的路径,其真实效果却引发了广泛争议。
近日,国外两位学者P.V. Coveney和S. Succi在最新研究论文中提出了警示:规模定律在提升大语言模型(LLM)预测不确定性方面存在根本性缺陷,难以通过常规手段将可靠性提升至科学探索所需的严格标准。他们形象地将这一盲目追求规模扩张的趋势称为“退化式AI”,意指在此过程中,错误与不准确性将以灾难性的方式累积。

两位学者指出,LLM的核心学习机制——从高斯输入分布生成非高斯输出分布——可能是导致错误累积、信息灾难及退化式AI行为的根源。他们呼吁,为避免这一困境,应回归问题本质,利用物理规律、问题导向的小规模网络,并结合人类的深刻洞察与理解,而非仅仅依赖规模的盲目扩张和资源的过度投入。
尽管LLM在自然语言处理领域取得了令人瞩目的成就,甚至不时被吹捧为“超越人类水平”,但这种发展趋势并未能如预期般解决科学领域的诸多挑战。实际上,LLM的成功案例,如国际象棋与围棋的胜利、对蛋白质结构的预测等,虽然成为广泛讨论的话题,但其在科学和社会领域的应用仍面临本质缺陷。尤其是,机器学习本质上是一种数学“黑箱”程序,缺乏对底层物理学的理解。
当前,只有少数AI科技公司具备训练大型前沿LLM的能力,而这些模型对电力的需求近乎无穷,甚至计划在数据中心旁建设核反应堆以满足其庞大的能源需求。然而,尽管这些公司严密保护其AI能力,不公开技术细节,但已有迹象表明,其性能提升的空间实则相当有限。以GPT-4.5为例,尽管其参数量巨大,API成本高昂,但在数学与科学等可验证领域,其进步微乎其微。
LLM的扩展性也面临严峻挑战。即使是最先进的AI聊天机器人,也会产生明显错误,这与科学应用所要求的精度标准相去甚远。研究团队通过“导数”的例子说明,随着模型规模的扩大,可能会遭遇更多潜在的“壁垒”,导致准确性不仅无法提升,反而可能显著下降。数字系统易受舍入误差影响,随着复杂性和操作数量的增加,这种影响愈发明显。
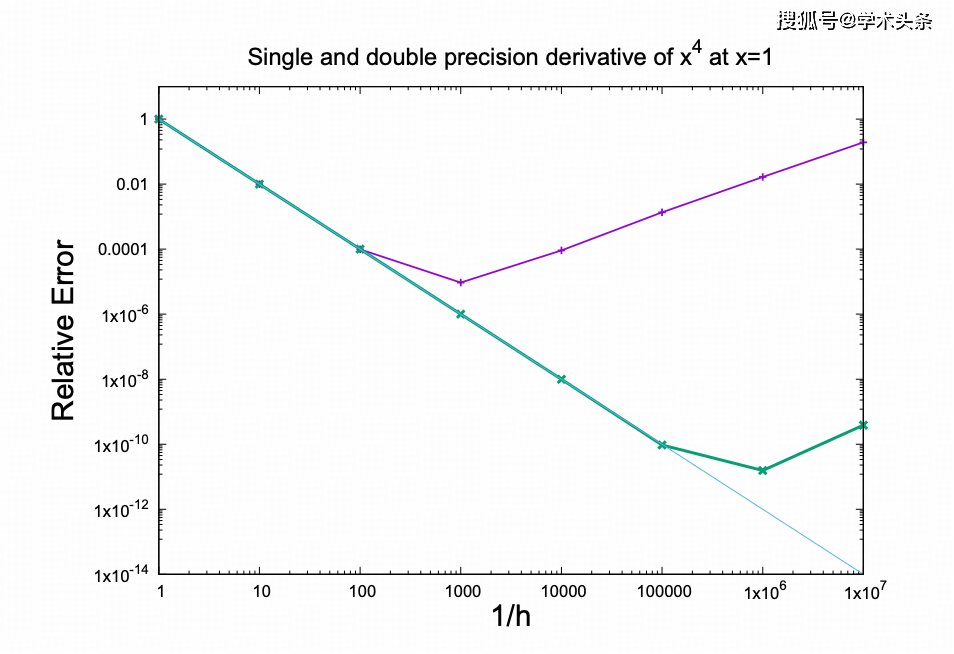
业内普遍认为,机器学习应用的准确性高度依赖于训练数据集的同质性。然而,即使在同质的训练场景下,准确性问题也屡见不鲜。缺乏泛化能力始终是机器学习面临的关键问题,因为泛化才是真正意义上的学习能力。尽管LLM常被赞扬为具有预测未见数据的能力,但这种能力的可靠性仍存疑。
鉴于LLM的局限性,科技行业正尝试通过大型推理模型(LRM)和代理式AI来提高模型输出的可信度。然而,这些策略的有效量化更为困难,且缺乏严谨的科学评估标准。尽管LRM在某些方面带来了改进,但同样高度依赖经验基础;而代理式AI虽然能让LLM超越单纯聊天工具的功能,产生实际经济价值,但从科学角度看,其评估标准仍显不足。
研究团队提出,或许更应让LLM发挥其生成式模型的特长,即“幻觉”能力。通过推理模型和多轮工具的使用,可以引导这种幻觉,将生成的不确定性转化为探索价值。例如,AlphaEvolve就采用了类似策略,利用LLM想象代码变体,并通过进化算法指导选择和改进。
两位学者强调,退化式AI虽然是当前大模型的一种内在可能性,但并非不可避免。他们呼吁,应构建“世界模型”,从庞杂数据中识别和提取真实相关性,剥离虚假相关性。简单依赖规模扩张而忽视科学方法,无疑是一条注定失败的道路。











