在人工智能领域的最新进展中,一项名为ScienceBoard的创新项目正悄然改变科学研究的方式。该项目由香港大学、上海人工智能实验室、复旦大学、北京大学以及耶鲁大学的研究人员共同推进,旨在构建一个面向科学任务、真实交互、自动评估的多模态智能体评测环境。
近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的迅猛发展,AI在诸多领域如自然语言处理、编程、图像理解等方面取得了显著成就。然而,在科学研究这一关键领域,AI的角色转变尤为引人注目。从最初的数据分析助手,到如今能够主动参与科研工作的智能体,这一变化标志着AI正成为科研人员的得力伙伴。
ScienceBoard项目的提出,正是为了应对这一转变所带来的新挑战。传统的AI助手多局限于语言理解和生成,而现代科研任务则要求智能体能够操作复杂的科研软件,理解科学概念,以及在不同模态的信息间进行有效推理。然而,现有的多模态智能体系统大多针对网页、电商、编程等通用任务,难以满足科研工作的实际需求。
为了填补这一空白,ScienceBoard项目团队构建了一个基于Ubuntu虚拟机的多模态科学探索环境。该环境集成了多个开源科研软件,覆盖了生物化学、天文模拟、地理信息系统等多个科学领域,并提供了图形用户界面(GUI)和命令行界面(CLI)双模态操作接口。ScienceBoard还配备了一套自动初始化机制和可扩展的任务评估函数,确保评测的可复现性和准确性。

ScienceBoard的核心在于其系统化、具挑战性的科研任务集合。这些任务不仅覆盖了多种科研软件,还充分考虑了任务的多样性、复杂度和可执行性。为了确保任务的真实性和复杂性,项目团队采用了人工设计加程序验证的混合标注流程,确保每个任务都基于真实软件手册构思,并通过多轮交叉验证确保其合理性和可评估性。
在ScienceBoard评测基准上,项目团队对当前代表性的商业模型、开源模型以及GUI基座模型所构建的智能体进行了评估。结果显示,即便是当今最强的多模态大模型,在真实科研工作流中的表现也远未成熟。例如,GPT-4o和Claude 3.5等商业大模型在整体任务成功率上仅达到约15%。这一结果揭示了科学工作流的复杂性,以及当前模型在执行策略上的不足。
进一步的分析实验还表明,许多失败的智能体实际上“知道要做什么”,但在执行过程中却“做不好”。以GPT-4o为代表的模型在任务规划上展现了强大的理解能力,但在面对真实界面时,常因点击不准或路径偏差而执行失败。这一现象表明,当前模型在理解和执行之间仍存在明显的断层。
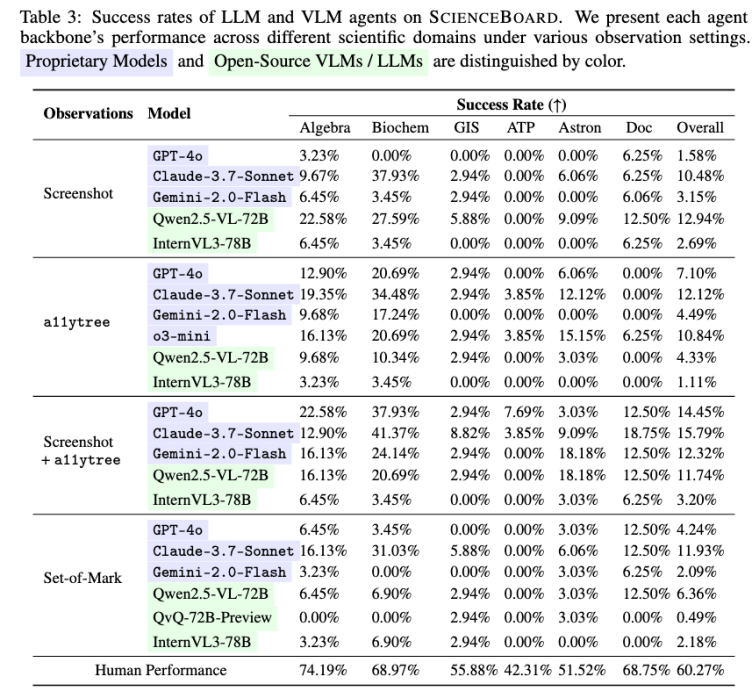
为了应对这一挑战,项目团队尝试将规划(Planning)与执行(Action)解耦,构建模块化智能体系统。由GPT-4o等模型负责生成高阶计划,再由各类开源VLM或GUI Action Model执行具体操作。实验结果显示,这种模块化设计显著提升了成功率,尤其在界面复杂、操作链条长的科研软件任务中表现更为突出。
ScienceBoard项目的成功实施,不仅为科学研究的智能化探索提供了一个可复现、可衡量、可扩展的起点,还为未来智能体系统的发展指明了方向。随着技术的不断进步和应用的不断拓展,AI在科学研究中的角色将更加多样化和深入,为人类的知识积累和创新发展注入新的活力。