随着人工智能领域对算力的需求呈现指数级增长,大智算集群已成为模型训练不可或缺的基础设施。这一趋势的背后,是模型参数与数据量的不断膨胀,驱动着算力需求的急剧上升。从GPT、Llama到Grok等主流模型的发展历程中,算力需求的增长尤为显著,Grok-4等最新模型的算力需求已较早期模型提升了近千倍。
在大规模集群训练的场景下,算力需求的增长带来了前所未有的挑战。以DeepSeek、Kimi K2及GPT-4等模型为例,其训练所需的算力及时间成本均极为高昂。即便是采用高性能的英伟达H100集群,训练这些模型也需耗费数十天乃至数百天的时间。因此,单纯依靠扩大集群规模已难以满足当前的算力需求,亟需探索新的解决方案。
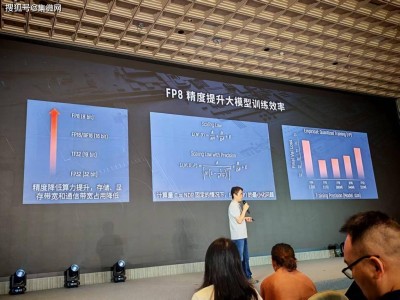
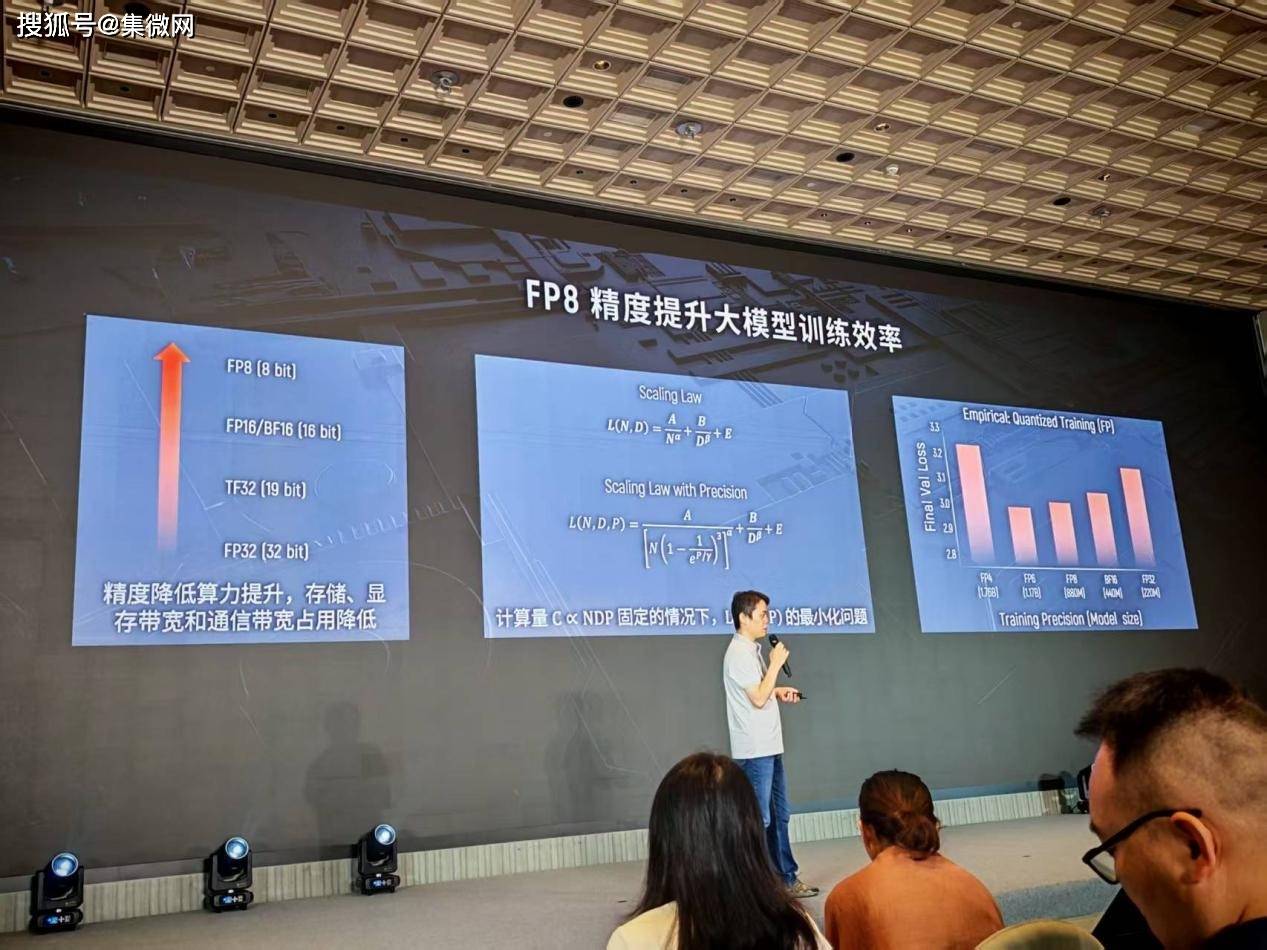
在这一背景下,低精度训练成为了提升训练效率的关键途径。从FP32到FP16,再到如今的FP8,精度的降低带来了算力的显著提升。然而,精度的下降也伴随着模型效果的损失。如何在精度与算力之间找到平衡点,成为了业界关注的焦点。摩尔线程副总裁王华在WAIC2025期间的摩尔线程技术分享日上,以《基于FP8的国产万卡训练》为主题,分享了摩尔线程在这一领域的创新与思考。
王华指出,通过引入精度参数,可以构建新的Scaling Law模型,从而在参数量、数据量与精度之间找到最优配置。实验结果表明,FP8成为了精度与算力之间的最佳平衡点。然而,低精度训练也面临着诸多挑战,如数值范围小、易上溢下溢等问题。为解决这些问题,摩尔线程采用了混合精度训练等技术手段,对非敏感部分采用FP8进行计算,而对敏感部分则继续使用高精度。
在软硬件支持方面,摩尔线程提供了全栈的完整解决方案。硬件上,其GPU支持从FP64到FP8的全精度算力;软件上,摩尔线程推出了Torch-MUSA、MT-MegatronLM及MT-TransformerEngine等开源框架,这些框架均支持FP8混合精度训练,并实现了对FP8数据类型的完整支持。在此基础上,摩尔线程成功复现了DeepSeek-V3的整个训练过程,成为业内率先能复现DeepSeek满血版训练的厂商。
王华还分享了摩尔线程在FP8训练上的探索与实验。在scaling factor的选择及outlier的影响等方面,摩尔线程进行了深入的研究,并提出了有效的解决方案。例如,在scaling factor的选择上,摩尔线程采用了Per-Tensor及JIT动态的scaling factor选择策略;在降低outlier影响方面,则采用了Smooth SwiGLU等技术手段。
在大规模集群训练方面,摩尔线程同样取得了显著的进展。为提高集群训练的可靠性,摩尔线程引入了起飞检查、飞行检查及落地检查等训练生命周期管理措施。同时,针对慢节点及容错训练等问题,摩尔线程也提出了相应的解决方案。例如,在慢节点检测方面,摩尔线程通过起飞检查阶段的小工作负载测试及训练过程中的通信执行时间监测等手段,有效识别并解决了慢节点问题;在容错训练方面,则采用了动态摘除故障节点等策略,确保了集群训练的持续稳定运行。

王华的分享不仅展示了摩尔线程在FP8低精度训练及大规模集群训练方面的创新成果,也为业界提供了宝贵的参考与借鉴。随着人工智能技术的不断发展,摩尔线程将继续深耕这一领域,为人工智能的未来发展贡献更多力量。