国产GPU领域近期捷报频传,技术突破不断引发业界关注。砺算科技的7G01芯片凭借卓越性能,已成功跻身RTX 4060级别行列,而摩尔线程亦不遑多让,其高性能GPU不仅在游戏领域大放异彩,AI应用同样成为其发力重点。
提及AI领域的GPU强者,NVIDIA无疑占据领先地位,其硬件架构与CUDA生态构建的壁垒,令众多竞争者望尘莫及。国产GPU与之相比,究竟存在多大差距?这一话题在知乎等平台引发广泛讨论。业内用户@菽陌松囿通过实际测试,提供了一系列数据,为公众提供了有价值的参考。
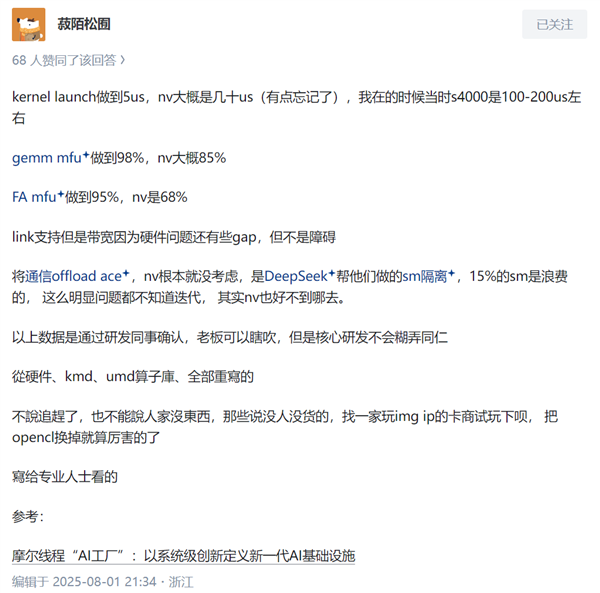
据@菽陌松囿透露,摩尔线程的GPU在kernel launch方面表现优异,用时仅为5微秒,相比之下,NVIDIA的同类产品则需几十微秒(具体数值有所遗忘)。在gemm mfu效率上,摩尔线程达到了98%,而NVIDIA约为85%。在FA mfu效率上,摩尔线程同样以95%的成绩领先,NVIDIA则为68%。
值得注意的是,@菽陌松囿还指出了NVIDIA GPU的一些不足,如通信offload ace功能的缺失,以及sm隔离方面存在的浪费问题。据悉,DeepSeek曾助力解决sm隔离问题,但仍有15%的sm资源未能得到充分利用。
当然,摩尔线程的GPU亦非尽善尽美。例如,在支持Link功能方面,其带宽仍受限于硬件条件,与理想状态存在一定差距。然而,@菽陌松囿强调,这些不足并非不可克服的障碍。
他进一步表示,上述数据均经过研发团队的严格确认,确保其真实可靠。此番对比结果令人惊喜且意外,显示出国产GPU在AI领域的强劲实力。他透露,摩尔线程的GPU从硬件到kmd、umd算子库均实现了全面重写,有力回击了关于其缺乏核心技术的质疑。
为了更全面地了解摩尔线程GPU的技术优势,公众可参考其官方发布的相关文章。虽然该文章未直接对比NVIDIA数据,但结合@菽陌松囿提供的数据对比,我们仍能窥见国产GPU在AI领域的出色表现。这无疑打破了部分网友关于国产GPU仅为国外IP套壳的片面观点。