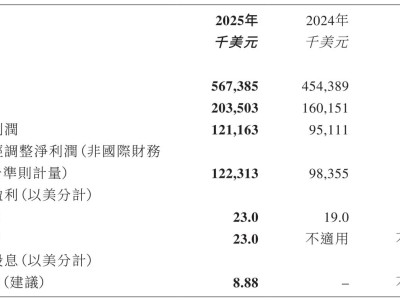
麻省理工学院(MIT)携手英伟达、苏黎世联邦理工学院等机构,共同推出了一项名为“驯服长尾”(TLT)的创新技术,旨在显著提升推理大语言模型(LLM)的训练效率。这一突破性成果,为人工智能领域的高效训练提供了新的解决方案。
推理大语言模型在解决复杂问题时展现出强大的能力,通过拆解步骤逐步推导答案。然而,在强化学习(RL)的训练过程中,这类模型对算力和能耗的需求极为庞大。研究团队深入分析后发现,在训练过程中,生成多个备选答案的“推演”阶段占据了总训练时间的85%。由于不同处理器处理任务的速度不同,完成较快的处理器往往需要等待其他处理器处理长文本任务,导致大量时间被浪费,形成了严重的效率瓶颈。
为了解决这一问题,MIT的研究人员与合作伙伴共同提出了“驯服长尾(TLT)”自适应解决方案。该方案的核心在于引入“投机解码”技术,即利用一个较小的“草稿模型”快速预测大模型的未来输出,再由大模型对这些预测进行批量验证。这种方式避免了逐个顺序生成输出的传统模式,从而大幅加快了处理速度。
在传统的投机解码方法中,草稿模型通常只训练一次并保持静态。然而,在强化学习过程中,主模型需要更新数千次,静态草稿模型很快就会失效,无法与主模型保持同步。为了克服这一挑战,TLT系统引入了“自适应草稿训练器”。当部分处理器完成短查询任务后进入闲置状态时,系统会立即调度它们实时训练草稿模型,确保草稿模型始终与目标大模型保持高度同步。
TLT系统还配备了“自适应推演引擎”,能够根据工作负载特征自动调整解码策略,确保在不增加额外算力开销的情况下,实现草稿模型与目标大模型的高效协同。这一创新设计使得训练过程更加灵活和高效。
基于真实世界数据集的测试结果显示,TLT技术在保持模型准确率完全无损的前提下,将多个推理大语言模型的训练速度提升了70%至210%。这一成果不仅显著缩短了训练时间,还降低了能耗和成本,为人工智能的大规模应用提供了有力支持。
值得一提的是,训练过程中得到的轻量级草稿模型还可以作为副产品直接用于后期的高效部署。这一特性进一步提升了TLT技术的实用价值,为人工智能模型的优化和部署提供了新的思路。研究团队计划将该技术融入更多训练与推理框架中,以进一步降低AI开发成本并提升能源利用率。