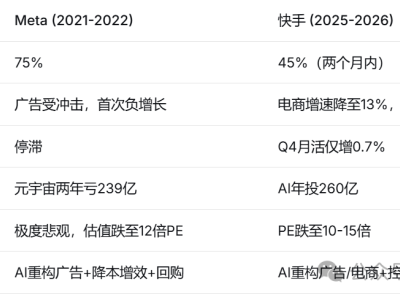
小米公司近日通过其官方公众号“Xiaomi MiMo”宣布了一项重大技术进展——正式开源了首个专注于推理能力的大型语言模型MiMo。该模型拥有70亿参数,小米官方强调,MiMo在数学推理和代码竞赛等多个公开测评中展现出了卓越的性能,甚至超越了OpenAI的闭源模型o1-mini以及规模更大的阿里开源模型Qwen2.5-32B。
小米技术团队深入揭示了MiMo背后的技术创新。他们指出,模型的成功得益于预训练与后训练阶段的协同优化策略。在预训练阶段,团队精心挖掘并合成了约2000亿tokens的高质量推理语料,通过三阶段渐进训练策略,累计训练量达到了惊人的25万亿tokens,为模型打下了坚实的基础。
进入后训练阶段,小米引入了创新的强化学习技术,包括自主研发的“测试难度驱动奖励”算法和“简单数据重采样”策略。这些创新技术有效提升了模型在处理复杂任务时的稳定性和准确性。技术团队还开发了“无缝部署”系统,使得训练效率提高了2.29倍,验证速度加快了1.96倍,进一步加速了模型的优化和应用。
小米官方特别指出,在相同的强化学习训练数据下,MiMo-7B在数学与代码领域的表现明显优于当前业界广泛使用的DeepSeek-R1-Distill-7B和Qwen2.5-32B模型。这一对比结果进一步验证了MiMo在推理能力上的显著优势。

为了推动人工智能领域的技术进步和开放共享,小米已在HuggingFace平台上开源了MiMo-7B全系列的四个模型,并发布了详细的技术报告。这一举措不仅展示了小米在AI技术领域的深厚积累,也为全球开发者提供了一个宝贵的资源,共同推动人工智能技术的创新与发展。