在人工智能领域,超级智能(Superintelligence)的概念正逐渐从科幻走向现实,它超越了通用人工智能(AGI)的范畴,预示着一种在各方面能力都远超人类的智能形态。近日,科技巨头meta宣布斥资数十亿美元秘密建立超级智能实验室,此举引发了业界的广泛关注。
meta的大手笔投入只是冰山一角,OpenAI、Anthropic和Google DeepMind等头部企业也纷纷表达了构建超级智能机器的雄心壮志。OpenAI的首席执行官Sam Altman更是直言不讳,他认为构建超级智能是一个工程问题,而非纯粹的科学难题,这似乎暗示了他们已经掌握了通往超级智能的关键路径。
然而,对于如何实现超级智能,业界内部存在着激烈的争议。meta AI的研究员Jack Morris就对当前基于大语言模型(LLM)的强化学习(RL)路径提出了质疑。他认为,尽管LLM在训练分布内的任务上表现出色,但它们并不足以构成一个单一的超级智能模型。
Morris在博客“Superintelligence, from First Principles”中探讨了构建超级智能的三种可能方式,包括完全由监督学习(SL)、来自人类验证者的RL以及来自自动验证器的RL。他指出,将非文本数据整合到模型中并未带来整体性能的提升,因为人类撰写的文本具有某种内在价值,这是其他模态数据所无法比拟的。

在Morris看来,数据是实现超级智能的关键。他强调,目前最好的系统都依赖于从互联网的文本数据中学习,而非文本数据如图像、视频等并未对提升LLM的智能水平产生显著影响。这一观点引发了关于数据类型的深入讨论,即文本数据是否真的是实现超级智能的唯一或最佳选择。
除了数据类型,学习算法也是实现超级智能的关键因素之一。在机器学习领域,SL和RL是两种基本的学习方法。SL通过训练模型以增加某些示例数据的概率,而RL则涉及从模型中生成数据,并根据其采取的“良好”行动给予奖励。
对于SL路径,一些人认为通过大量的SL,特别是以“next-token prediction”的形式,可能导致超级智能AI的出现。然而,这种逻辑也面临着挑战。尽管我们已经创建了在next-token prediction方面远超人类水平的系统,但这些系统仍无法展现人类级别的通用智能。随着模型规模的扩大,数据不足和硬件限制也成为了制约SL路径进一步发展的瓶颈。
相比之下,RL路径提供了通过反馈而非仅依赖演示进行学习的可能性。然而,RL也面临着诸多挑战,如冷启动问题、奖励稀疏性等。为了克服这些挑战,人们开始探索结合SL与RL的方法,即先通过SL进行预训练,然后利用RL进行微调。

在结合SL与RL的方法中,来自人类验证者的RL和来自自动验证器的RL是两种主要的方式。前者依赖于人类提供的奖励信号来训练模型,后者则利用自动验证器来评估模型的性能并给予奖励。尽管这两种方式都具有一定的潜力,但它们也面临着各自的挑战。
对于来自人类验证者的RL,数据收集成本高昂,且人类判断的主观性也可能影响模型的训练效果。而对于来自自动验证器的RL,虽然可以去除人类的参与,但目前可验证的任务类型有限,且RL在可验证任务上的迁移能力尚不清楚。
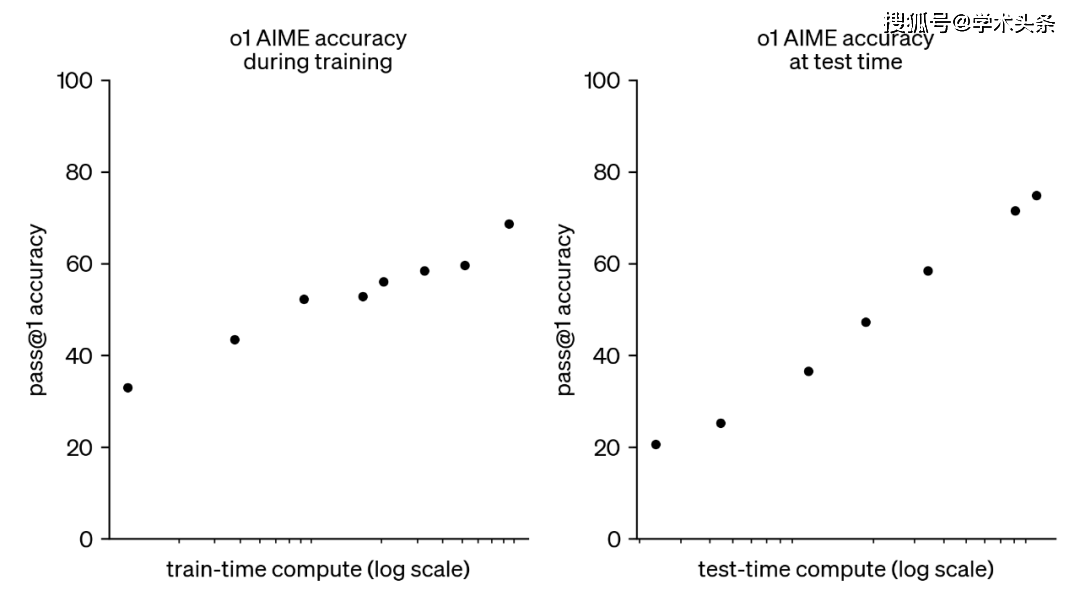
尽管如此,业界对于基于LLM的RL仍然充满了期待。OpenAI利用可验证奖励强化学习(RLVR)训练的o1模型已经取得了显著的成果,它能够通过更长时间的思考产生更优的输出。这一突破让人们看到了利用RL实现超级智能的可能性。
然而,通往超级智能的道路仍然漫长且充满挑战。尽管我们已经取得了一些进展,但距离实现真正的超级智能还有很长的路要走。在这个过程中,我们需要不断探索新的方法和技术,同时也需要保持谨慎和谦逊的态度,以应对可能出现的各种风险和挑战。