近期,人工智能领域迎来了一次重大飞跃,以大型语言模型(LLMs)为驱动的新型自主智能体正在逐步改变我们对智能系统的认知。这些智能体不仅能够感知环境输入,还能进行复杂推理并采取行动,形成了一个持续的交互循环。与传统AI系统相比,这种基于LLMs的智能体实现了从静态到动态的范式转变,它们拥有交互性和增强的记忆能力,使得AI的功能边界得到了前所未有的拓展。
然而,这一转变也伴随着新的安全风险。由于自主智能体能够在动态、开放式环境中执行多步任务,包括调用外部工具和修改数据库等,因此它们面临着记忆投毒、工具滥用、奖励操控以及价值错位导致的涌现性失配等多重威胁。这些风险远远超出了传统AI系统或独立LLMs的威胁模型范畴,对AI安全提出了新的挑战。
为了应对这些挑战,研究人员近年来提出了多种防御策略,涵盖输入净化、记忆生命周期控制、受限决策制定、结构化工具调用以及内省式反思机制等方面。然而,这些策略大多是孤立实施的,缺乏跨模块、跨时间维度的系统性响应能力,无法全面有效地应对智能体自主性增强带来的安全风险。
鉴于此,一项名为“反思性风险感知智能体架构”(R2A2)的新方案应运而生。这一统一的认知框架基于受限马尔可夫决策过程(CMDPs),融合了风险感知世界建模、元策略适应以及奖励–风险联合优化机制。R2A2旨在智能体的决策循环中实现系统化、前瞻性的安全保障,以确保智能体的行为始终与人类利益保持一致。
R2A2的提出,不仅标志着智能体自主性如何重塑智能系统的安全格局,也为下一代AI智能体的设计提供了理论蓝图。在这一蓝图中,安全性被视为核心设计原则,旨在通过构建准确、可解释的世界模型,生成因果假设,并在不确定性下进行推理,从而降低目标错配带来的风险。
从静态模型到基于LLMs的自主智能体,这一范式转变带来了显著的变革。传统AI系统通常依赖预定义规则或狭窄模型,难以泛化到预设范围之外。而基于LLMs的智能体则继承了底层模型的开放式问题解决能力,拥有更广阔的行动空间。它们可以在运行时阅读文档或动态上下文,即兴学会使用新工具,从而在社会中扮演通用助手的角色,解决各种复杂任务。
然而,这种高度自主性也带来了前所未有的安全挑战。自主智能体能够执行真实世界中具有后果的行为,如执行代码、修改数据库等,从而放大了系统故障与对抗性攻击的风险。因此,我们必须谨慎确保智能体的“对齐性”,即它们能够可靠地追求有益目标、配合人类监督,并能容忍设计上的不完美。

为了系统性理解自主性增强如何带来安全风险的升级,研究人员对三类AI系统的关键区别进行了总结与对比:传统AI、独立LLMs以及基于LLMs的自主智能体。这一对比涵盖了自主性水平、学习动态、目标形成、外部影响、资源访问能力与对齐可预测性等多个维度。通过这一结构化升级表,我们可以清晰地看到智能体架构漏洞与防御策略之间的关联,为后续研究提供了基本视角。
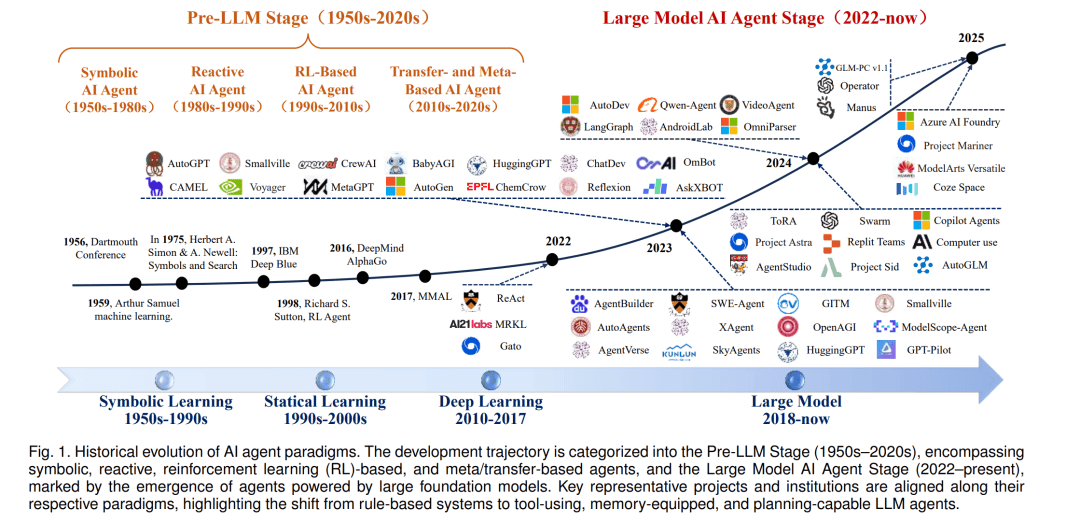
随着AI技术的不断发展,基于LLMs的自主智能体将在各个领域发挥越来越重要的作用。然而,我们必须时刻警惕它们带来的安全风险,并采取有效的防御策略来确保智能体的行为始终符合人类利益。R2A2架构的提出为我们提供了一个有力的工具,让我们能够在智能体的决策循环中实现系统化、前瞻性的安全保障,为AI技术的可持续发展奠定坚实基础。