在AI技术日新月异的今天,市场上的AI大模型如雨后春笋般涌现,从GPT-4到Claude,再到文心一言和DeepSeek,每一款模型都标榜着独特的优势。然而,面对如此繁多的选择,无论是普通用户还是企业,如何科学地挑选出最适合自身需求的AI大模型,成为了一个亟待解决的难题。本文将深入探讨一套实用的AI大模型选型策略。
AI大模型的选择之所以复杂,首要原因在于信息的碎片化。各类模型的相关信息散落在官网、技术博客及评测文章中,用户难以获取全面且客观的对比数据。各厂商倾向于强调自身的优势,却缺乏统一的评估标准,这无疑增加了用户的决策难度。
用户需求的多样性也是一大挑战。不同的用户有着不同的应用场景:有的需要强大的代码编写能力,有的则注重多语言翻译,还有的用户更看重成本效益。因此,单一的性能排名远远无法满足用户的个性化需求。
再者,AI大模型的技术门槛相对较高。模型参数、推理速度、上下文长度等技术指标对于非专业用户来说晦涩难懂,更别提将这些指标与实际应用需求相结合了。因此,一套科学的选型方法论显得尤为重要。
科学的AI大模型选型方法论首先要求建立全面的评估维度体系。这一体系应涵盖基础能力、技术性能、应用场景以及商业考量等多个方面。基础能力维度包括文本理解与生成质量、逻辑推理能力、知识储备广度与深度以及多语言支持程度;技术性能维度则涉及响应速度与延迟、上下文窗口长度、并发处理能力以及模型稳定性;应用场景维度需考虑代码编程能力、创意写作水平、数据分析功能以及多模态处理能力;而商业考量维度则包括使用成本与计费方式、API接入便利性、服务可用性与技术支持以及数据安全与隐私保护。
在确立了评估维度之后,量化评估方法同样不可或缺。目前,业界主要采用MMLU、Humaneval、GSM8K等标准化测试集来评估模型能力。然而,除了标准化测试外,真实场景测试同样重要。这包括任务完成质量、用户满意度以及错误率等指标。成本效益分析也是选型过程中不可忽视的一环。用户需综合考虑模型性能与使用成本,计算出性价比指标,从而做出最优选择。
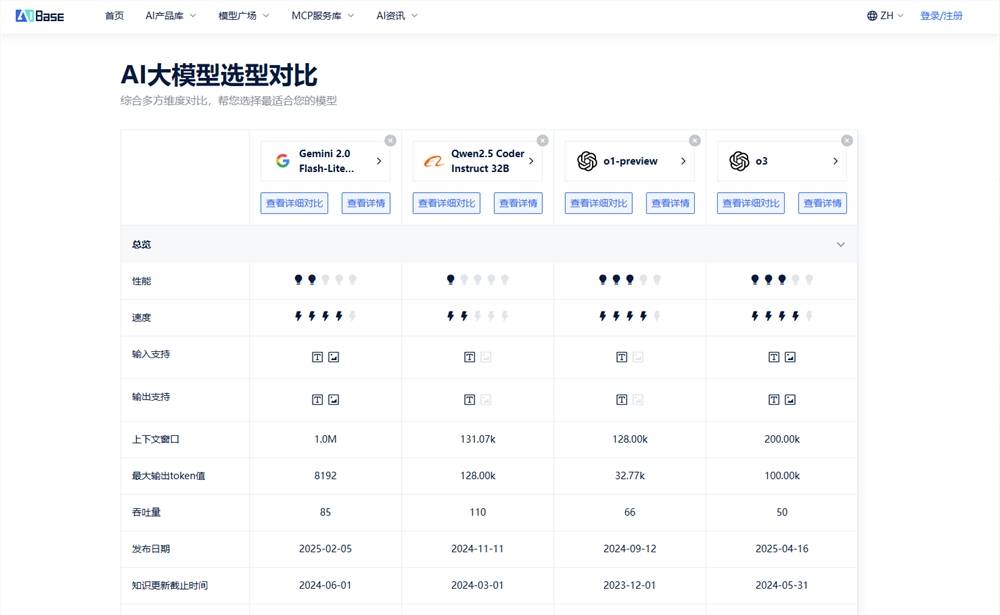
以2025年的主流AI大模型为例,GPT-4系列以其卓越的多模态实时交互能力脱颖而出,适用于通用对话、创意写作及复杂推理等场景;Claude系列则凭借深度思考和编程能力备受瞩目,适用于代码开发、学术写作及逻辑分析;Gemini系列则以百万token窗口和内置思考能力开创新标准,适用于大文档处理及多模态任务。国产模型方面,DeepSeek系列凭借UltraMem架构与开源生态,在成本效益方面表现出色;文心一言则在中文理解和搜索集成方面具有优势,特别适合国内用户;通义千问则在商业应用和企业服务方面拥有完善的生态支持。
对于个人用户而言,若需日常对话助手,GPT-4或Claude无疑是不错的选择;若需学习辅助,则应选择在教育领域经过优化的模型;若热衷于创意写作,则应关注文本生成质量高的模型。对于企业用户来说,客服机器人需具备稳定性和成本控制能力;内容生产则需注重创意能力和效率;数据分析则需选择逻辑推理能力强的模型。而对于开发者来说,Claude或专门的代码模型可作为代码助手;API集成则需考虑接入便利性和文档完善度;若对成本敏感,DeepSeek等高性价比选择则更为合适。
面对如此复杂的选型过程,普通用户往往难以独立完成全面的模型对比。此时,专业的AI大模型对比平台便显得尤为重要。AIbase模型广场(https://model.aibase.com/zh/compare)便是一个值得推荐的平台。它提供了全面的模型数据库,实时更新模型性能数据和价格信息,并支持多维度的技术参数对比。该平台还配备了智能化对比工具,支持多模型同时对比,提供可视化的数据展示和个性化的推荐算法。用户还可以获取基于标准测试集的客观评分、真实使用场景的性能表现以及成本效益分析报告。
即便有了专业工具的帮助,最终的选择仍需通过实际测试来验证。大多数模型都提供免费试用额度,用户可以在真实场景下进行测试。同时,A/B对比测试也是一个有效的方法,即同时使用多个模型处理相同任务,对比输出质量和用户体验。长期观察模型的稳定性、更新频率和技术支持质量同样重要。
在AI技术快速发展的今天,掌握正确的选型方法比盲目追求最新模型更加重要。每个模型都有其独特的优势和适用场景,用户应根据具体需求进行选择。通过科学的评估体系、专业的对比工具以及实际测试验证,用户完全能够找到最适合自己的AI大模型。