在人工智能领域,视频大型语言模型(Video LLMs)正以前所未有的速度发展,它们能够精确描绘视频内容并准确回答相关问题,其表现令人惊叹,仿佛具备了人类级别的理解能力。然而,一个核心疑问始终困扰着研究人员:这些模型是真的“理解”了视频内容,还是仅仅在进行高级别的“模式匹配”?
为了解答这一疑问,南洋理工大学S-Lab的研究团队提出了一个全新的、极具挑战性的基准测试——Video Thinking Test(简称Video-TT)。该测试的核心目的在于将“观看”与“思考”的能力明确区分开来,从而精确评估AI在视频内容上的真实理解和推理水平。
研究团队在测试中发现了几个关键点:首先,人类在视频理解的准确性和稳健性方面远超当前的顶尖模型(SOTA),这一差距相当显著。其次,开源模型在稳健性上远远落后于GPT-4o这一SOTA模型之一。最后,GPT-4o也存在短板,如对模糊或非常规内容的识别能力较弱,难以区分、定位和计算多场景信息,以及缺乏对世界知识的对应能力,难以理解意图和社会动态等深层次信息。
Video-TT图灵测试集由南洋理工大学S-Lab科研团队与独立研究员联手研发,主要作者包括博士生张元瀚和董宇昊,他们的研究方向集中于多模态模型,通讯作者为南洋理工大学的助理教授刘子纬。
人类的智慧核心在于准确性和稳健性的结合。准确性使我们能够正确解读信息,而稳健性则确保我们在面对信息干扰、歧义或不同表述时,仍能维持正确的判断。这两者共同构成了真正可靠的理解能力。
现有的视频理解基准测试在衡量AI是否达到人类智慧方面存在根本性缺陷。它们往往无法区分模型是因“没看清”而犯错,还是因“没想明白”而出错。这种混淆使得评估AI在视频理解上的真实水平变得困难。
在Video-TT出现之前,视频理解领域已有评测标准,但这些标准存在局限性,导致AI的真实能力无法被准确衡量。长视频评测中,由于计算资源限制,模型无法处理视频的每一帧,只能稀疏采样,因此当模型答错时,我们无法确定是其能力不足,还是恰好错过了关键帧。而在短视频评测中,模型可以几乎“看完”所有帧,一些顶尖模型的表现接近甚至达到人类水平,这容易让人产生“短视频理解问题已被基本解决”的错觉,然而事实并非如此。
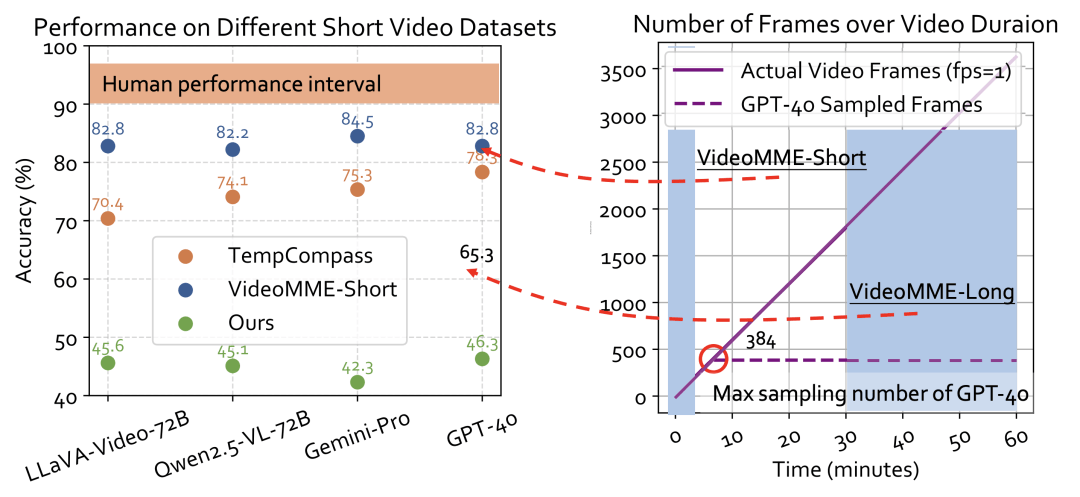
Video-TT的创新之处在于,它选择了1000条全新的YouTube短视频,并精心设计问题标注,确保答案能在有限的、统一的80帧内找到。这样一来,所有模型都在同一起跑线上“观看”素材,评测的焦点便转移到“能否深刻理解”上,直击AI的“思考”核心。
为了衡量“思考”,Video-TT提出了能够激发“思考”的问题。设计原则是,一个复杂的问题并非由其类型决定,而是由其背后的上下文、原因和场景决定。研究团队从认知科学和影视叙事学中汲取灵感,构建了两个核心的复杂性维度:视觉复杂度和叙事复杂度。
视觉复杂度关注视频画面的内在挑战,包括模糊与非常规内容、运动速度、时空布局和视错觉。而叙事复杂度则关注视频作为“故事”的表达方式,包括复杂情节、叙事剪辑、技术性剪辑和世界知识。
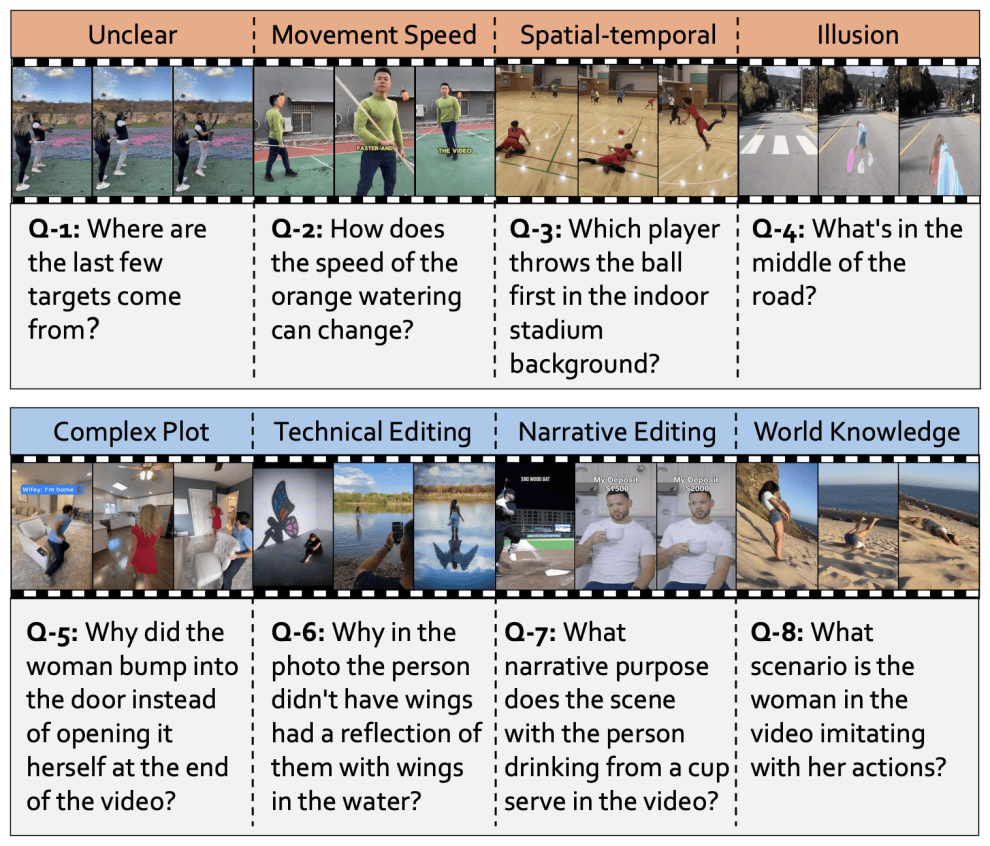
例如,一个关于“视频中的女士在模仿什么行为?”的问题,需要观众拥有特定的世界知识才能正确回答。这些问题迫使模型超越简单的物体识别,进入真正的推理层面。Video-TT还为每个核心难题配备了四种“自然对抗性问题”,以检验AI思考的稳健性。