在AI领域的一次重大转折中,OpenAI于北京时间8月6日凌晨震撼发布了其首个开源语言模型GPT-OSS,这一举动在全球科技界引发了广泛关注。尽管万众瞩目的GPT-5并未如期而至,但GPT-OSS的推出无疑预示着新一轮开源潮流的即将掀起。
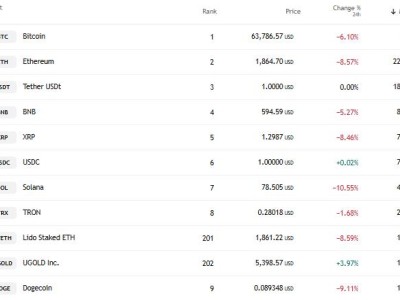
OpenAI此次发布的开源模型包括gpt-oss-120b和gpt-oss-20b两款。据OpenAI创始人奥特曼介绍,这两款模型性能卓越,达到了o4-mini的水平,更令人惊讶的是,它们可以在手机和笔记本等日常设备上运行。奥特曼将这一成就誉为技术上的重大胜利。
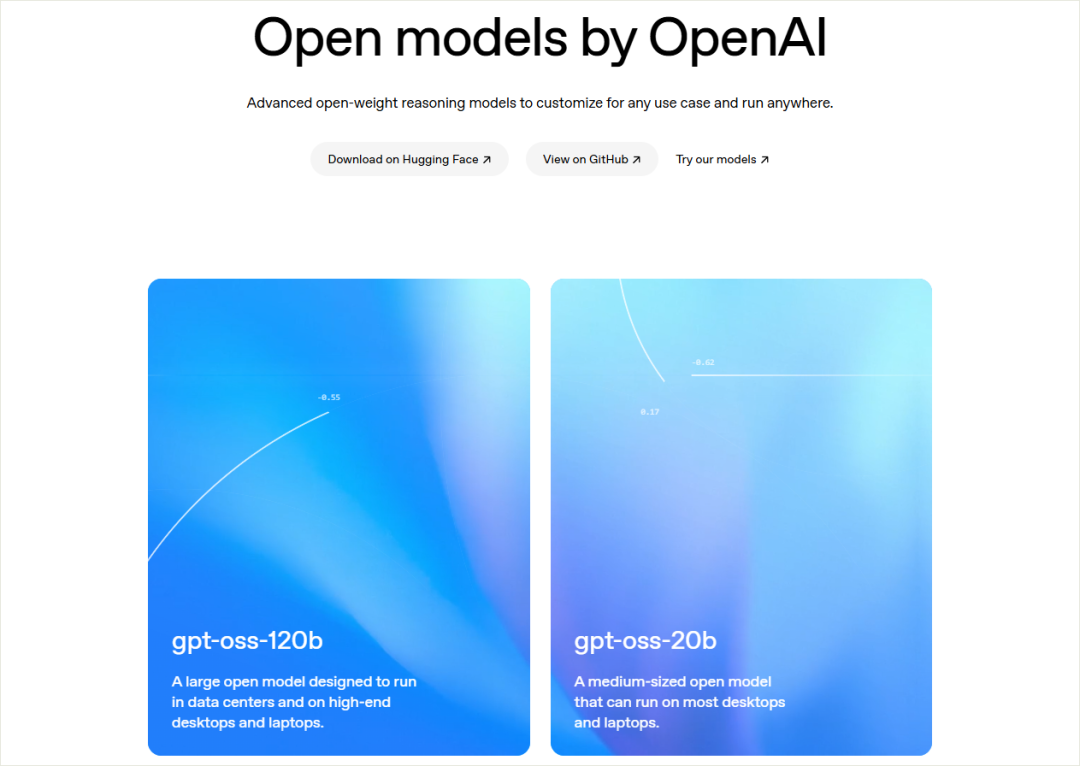
具体而言,gpt-oss-120b采用了先进的MoE架构,拥有高达1170亿参数,其中激活参数约为51亿。这款模型仅需单张80GB的GPU即可运行,其性能与闭源的o4-mini不相上下。而gpt-oss-20b同样基于MoE架构,拥有210亿参数,激活参数约36亿,它可以在配备16GB内存的设备上流畅运行,性能表现接近o3-mini。
回顾过去几年,OpenAI一直秉持“闭源+收费”的商业路线,无论是GPT-4还是GPT-4o,其核心模型始终未曾开放。业界也因此一度认为,“最强模型永远不会开源”。然而,GPT-OSS的出现彻底打破了这一固有观念。
OpenAI官方宣称,GPT-OSS是一款“小型但高效”的语言模型,其训练数据涵盖了多语种、多领域。更重要的是,OpenAI明确表示该模型“可以免费用于商业用途”,这一消息对中国乃至全球的AI初创企业而言,无疑是一大利好。

作为ChatGPT时代的开创者,OpenAI此次的举动意味着其商业路线的重大转变:从闭源独占走向开放协作的模型生态。这一转变是否意味着OpenAI要向国产大模型发起挑战?从OpenAI创始人奥特曼近期的动态来看,GPT-OSS的发布并非一时兴起,而是经过深思熟虑的战略调整。
近年来,中国的开源模型发展迅猛,先是有DeepSeek凭借R1版本掀起波澜,其凭借模型结构层面的突破性创新,大大降低了模型成本,被业内戏称为“AI届的拼多多”。此后,大批中国模型纷纷走上开源之路,其中阿里旗下的通义Qwen尤为突出。通义Qwen在全球社区中表现活跃,近三个月内经历了密集迭代,发布了多波重大更新,新增了数十个模型版本。
今年在世界人工智能大会上,有观点认为开源模型进入了“中国时间”。截至2025年8月,中国开源大模型生态蓬勃发展,除阿里通义(Qwen)外,还有多个影响力显著的开源模型团队,涵盖了基础模型、多模态、编程、轻量化等多个方向。这些中国对手们在编程、数学、多语言等领域正逼近甚至超越OpenAI的闭源模型。
中国开源模型的爆发式发展无疑触动了OpenAI以及硅谷的神经。颇为有趣的是,曾经主张开源策略的meta近期也在酝酿策略上的转向。据报道,meta人工智能实验室的新任负责人Alexandr Wang正考虑放弃meta的开源策略,转而开发闭源模型。这一转向无疑将使meta与OpenAI的较量更加激烈。