近日,科技新闻传出,苹果公司在其最新研究中提出了一项名为“多token预测”(MTP)的技术,该技术有望在不降低输出质量的前提下,显著提升大语言模型的响应速度。据称,在特定场景下,响应速度的提升幅度甚至可以达到5倍。
传统的大语言模型(LLM)在生成文本时,通常采用自回归方式,即逐个输出token。这种方式虽然保证了文本的连贯性,但每一步都依赖于前序内容,导致生成速度受限。特别是在移动设备上,这种串行机制可能会严重影响用户体验。
然而,苹果在其新论文《Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential》中发现,尽管模型被训练为预测下一个词,但其内部实际上具备对后续多个词的潜在判断能力。基于这一发现,研究团队提出了MTP框架,该框架支持模型一次生成多个词,从而大幅提升生成效率。
MTP技术的核心在于引入“掩码”token作为占位符,并让模型并行推测后续多个词。每个推测结果都会立即与标准自回归解码结果进行对比,如果不符,则自动回退到逐词生成模式。这一“推测-验证”机制在提升速度的同时,也保留了传统方法的准确性,实现了速度与质量的平衡。
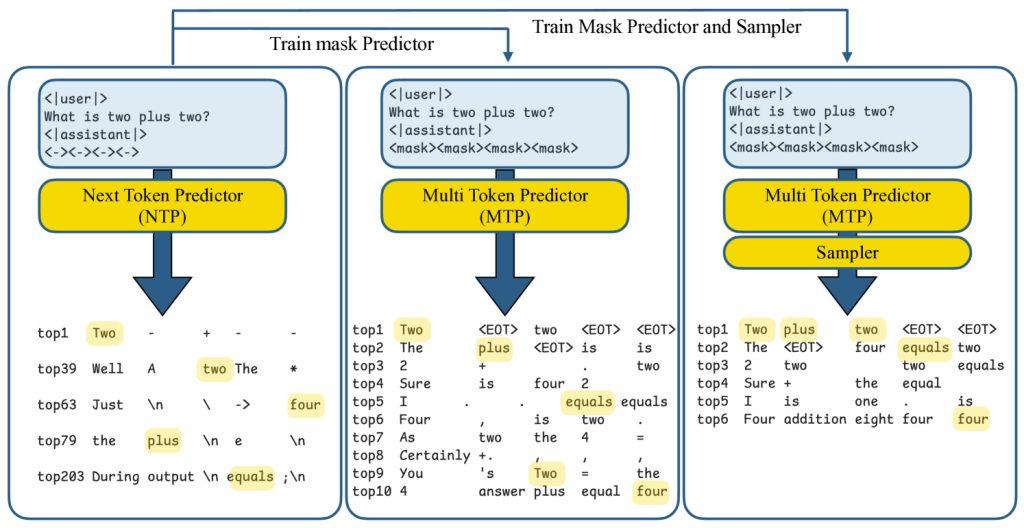
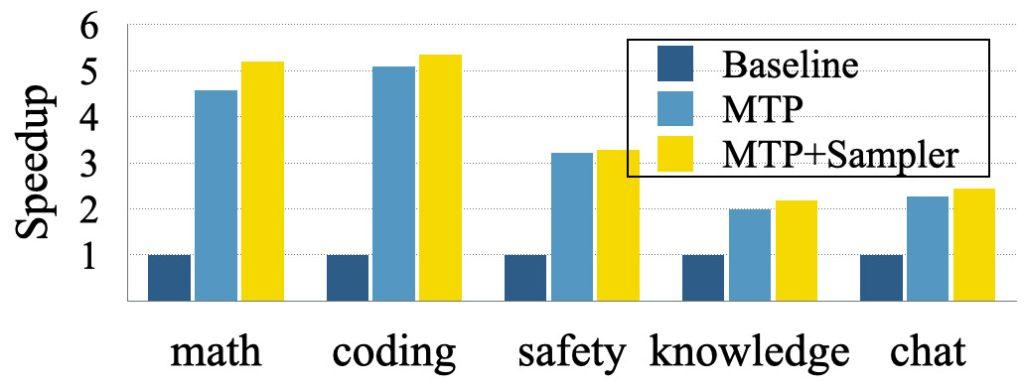
在实验中,苹果使用开源模型Tulu3-8B进行测试,并训练其最多推测8个后续token。结果显示,在问答、对话等通用任务中,MTP技术的响应速度平均提升了2至3倍;而在代码生成、数学推理等结构化场景中,提速更是达到了5倍。
值得注意的是,性能的提升并未以牺牲生成质量为代价。这得益于苹果采用的“门控LoRA适配”技术,该技术能够动态调节参数,仅在需要时激活推测模块。这一创新点确保了MTP技术在提升速度的同时,保持了高质量的输出。
MTP技术的提出,为设备端大模型的部署提供了新的可能。与依赖云端计算相比,MTP技术可以在iPhone、Mac等本地设备上实现更快响应,从而降低延迟和能耗。这对于提升用户交互体验具有重要意义。
尽管目前MTP技术仍处于研究阶段,但其兼容现有模型架构的特点使其具备较强的落地潜力。未来,该技术有望被集成至Siri、Apple Intelligence等苹果产品中,进一步提升用户的交互体验。