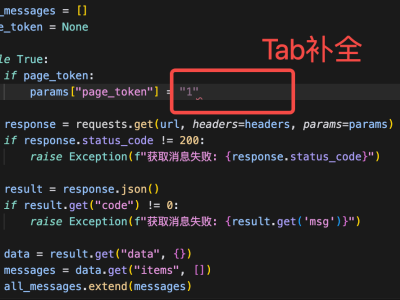
谷歌最新研究突破,为大型语言模型微调带来革命性变化,成功将训练数据需求量缩减至原先的万分之一,同时显著增强了模型判断的准确性,使之与人类专家水平更为接近,提升幅度高达65%。这一成果在广告内容甄别、金融数据风控等多个领域具有重大意义,尤其针对那些对训练数据质量有着极高要求的场景。
该创新流程起始于一个基础薄弱的模型,它能在几乎无样本或仅少量样本的情况下运作。用户通过具体指令,比如界定一则广告是否为误导性点击诱饵,引导模型进行初步分类。这一过程虽能快速生成大量标注数据,但往往伴随着严重的类别失衡问题,影响模型的精确识别能力。
面对这一挑战,研究者采取了巧妙策略。他们首先将模型标记的数据按类别分组,并发现了某些组别间的重叠现象,这揭示了模型在这些特定内容上判断的模糊地带。于是,从这些重叠组中精心挑选出的样本对,被提交给专家进行复核,以此确保审核成本得到有效控制,同时确保所选样本具有代表性和多样性,覆盖了模型可能犯错的多种情况。
在微调模型的过程中,专家提供的标注被一分为二:一部分用于检验模型与人类判断的一致性,另一部分则直接用于模型优化。这一循环迭代的过程持续进行,直至模型性能达到或接近专家水准。
实验阶段,谷歌选用了Gemini Nano-1和Nano-2两款模型,并针对两项难度各异的任务进行了验证。尽管初始的众包标注数据多达十万条且存在不平衡问题,但实验结果显示,专家间的判断高度一致,而众包标签与专家意见的一致性则相对较低。采用新方法后,拥有32.5亿参数的模型在简单任务上的表现有了显著提升,其所需数据量骤减至250至450条,相比原来的十万条数据大幅缩减,却仍能保持出色的效果。
这一研究不仅证明了,在确保专家标注一致性超过80%的前提下,即便是少量高质量数据也能驱动大型模型达到优异表现,同时也为未来的模型训练开辟了新的路径,强调了在数据稀缺或获取成本高昂的情况下,如何通过智能筛选和专家指导,实现模型性能的最大化。