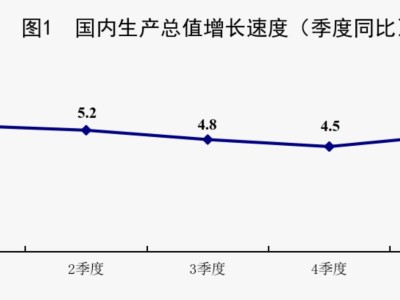
在机器人技术领域,五指灵巧手被视为实现类人操作的关键突破口。无论是拧开瓶盖还是精准传递物品,这类操作对机器人灵活性提出了极高要求。然而,一个核心难题始终制约着技术落地——训练数据的极度匮乏。
与依靠海量数据驱动的大语言模型,或通过大规模路测积累经验的自动驾驶系统不同,灵巧手操作数据的获取堪称"不可能任务"。传统方法暴露出多重局限:人工规划难以协调五指复杂动作,大语言模型仅能提供粗略方向,而遥操作采集成本高昂且难以形成规模化数据集。即便采用强化学习,机器人也常因探索效率低下而生成僵硬、抖动的动作轨迹。
现有数据集的局限性更为突出。多数仅针对单一抓取动作设计,当涉及倾倒液体、双手交接等复杂任务时便束手无策。轨迹回放技术虽能在固定场景微调位置,但无法创造新策略,数据多样性严重不足。这种"实验室孤岛"现象,导致灵巧手技术长期难以突破到真实应用场景。
转折点出现在北京大学、哈尔滨工业大学与PsiBot灵初智能团队的联合研究中。他们提出的DexFlyWheel框架,以颠覆性思路破解了数据困局——仅需1条人类演示视频,即可启动"数据飞轮"生成海量多样化训练数据。这项被NeurIPS 2025会议选为Spotlight的研究(入选率仅3.2%),揭示了灵巧操作数据生成的全新范式。
研究团队发现,不同物体间的操作差异具有规律性:形状相似的物体(如苹果与橙子),仅需微调手指角度和力度即可完成抓取。基于这一洞察,他们构建了模仿学习与残差强化学习的协同机制。前者确保动作自然流畅,后者负责精准适配新场景,二者形成"粗调-细调"的闭环优化。
更具创新性的"数据飞轮"循环机制,通过VR采集的1条种子演示启动:扩散策略模型首先学习人类操作模式,生成初始轨迹;残差强化学习在此基础上微调,形成适应新物体的策略;仿真环境中的轨迹验证又为下一轮训练提供数据。这种滚雪球效应使数据量呈指数级增长——1条演示可扩展出500条轨迹,场景复杂度提升214倍,物体种类从1种增至20种。
实验数据验证了框架的优越性:在单手抓取、双手交接等任务中,数据生成成功率达89.8%,较传统轨迹回放提升显著;生成500条轨迹仅需2.4小时,效率是人工演示的1.83倍。更关键的是,策略在复杂测试集中的成功率从16.5%跃升至81.9%,通过数字孪生技术部署到实体机器人后,双手提起任务成功率仍保持78.3%。
这项突破的意义不仅在于数据量的提升,更在于开创了"数据自我进化"的新路径。当前框架虽尚未集成触觉感知模块,但研究团队已规划将其作为下一阶段重点。若能解决触觉反馈与自动化奖励设计问题,机器人将有望掌握组装精密零件等更高阶技能,向通用灵巧手目标迈出关键一步。