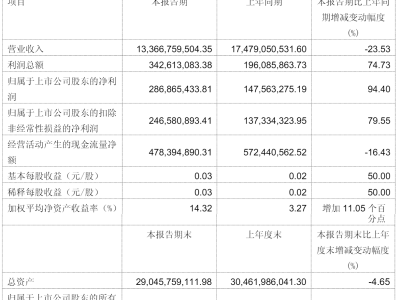
苹果公司与俄亥俄州立大学科研团队近日共同发布了一项语言模型领域的突破性成果——名为“少步离散流匹配”(FS-DFM)的新型生成模型。该模型通过创新算法设计,在保持长文本生成质量的同时,将迭代次数从传统模型的千次级压缩至8次,生成效率较同类技术提升最高达128倍,为大规模语言模型的高效应用开辟了新路径。
作为扩散模型的改进版本,FS-DFM的核心创新在于三阶段动态优化机制。研究团队首先通过多尺度训练策略,使模型具备适应不同迭代次数的自适应能力;其次,引入“教师-学生”模型架构,利用预训练的高精度模型作为引导,确保每次迭代都能精准修正生成方向;最后,通过优化迭代路径的离散化设计,大幅减少无效计算步骤。这种分层优化策略使得模型在极低迭代次数下仍能保持输出稳定性。
实验数据显示,FS-DFM在参数量仅为1.7亿至17亿的轻量化配置下,性能表现显著优于参数量数十倍的现有模型。与70亿参数的Dream模型和80亿参数的LLaDA模型对比测试中,该模型在困惑度(Perplexity)和熵值(Entropy)两项核心指标上均取得更优结果,生成的文本不仅语义连贯性更强,且在长距离依赖场景下的逻辑一致性提升明显。特别是在需要保持上下文连贯性的长文本生成任务中,FS-DFM展现出了独特的效率优势。
这项研究通过算法层面的范式革新,为语言模型的大规模应用提供了新的技术路线。其核心价值在于突破了传统模型“以算力换质量”的固有模式,在显著降低计算资源消耗的同时,保持甚至提升了生成质量。随着模型轻量化与效率提升的双重突破,该技术有望在实时交互、动态内容生成等对响应速度要求严苛的场景中发挥关键作用。