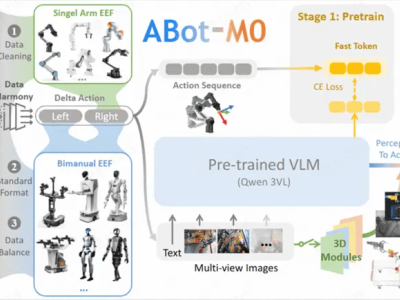
谷歌近期在机器学习领域迈出重要一步,推出名为“嵌套学习”的创新范式。该理论突破传统框架,将模型训练重构为多层次嵌套优化问题,旨在解决大型语言模型(LLM)的灾难性遗忘难题,推动AI向类人持续学习能力演进。相关研究论文《嵌套学习:深度学习架构的错觉》已发表于NeurIPS 2025。
传统LLM的认知局限源于其“静态知识”特性——模型能力被冻结在预训练阶段或即时上下文窗口中。尽管通过持续微调可引入新知识,但这种“填鸭式”更新必然导致原有知识的灾难性丢失。过往研究试图通过架构调整或优化算法改良缓解问题,却始终未能突破“模型结构”与“学习规则”的二元割裂。
嵌套学习的核心突破在于重构认知维度。研究团队提出,复杂AI模型本质是不同时间尺度优化的嵌套系统:从瞬时参数调整到长期知识沉淀,各层级优化问题通过差异化更新频率形成动态平衡。这种视角将传统分离的模型架构与训练算法统一为多层次优化问题,每个层级既独立处理特定信息流,又通过梯度传递形成协同。
以Transformer架构为例,嵌套学习揭示其注意力机制本质是低频更新的联想记忆模块,而反向传播过程则对应高频误差校正。通过为各组件分配不同更新频率,模型可模拟人脑神经可塑性——高频层捕捉即时信息,低频层整合长期知识,中频层协调两者冲突。这种多时间尺度更新机制,为解决灾难性遗忘提供了结构化方案。
基于该理论,研究团队开发出概念验证模型Hope。作为Titans架构的进化版,Hope突破原有双层级更新限制,通过循环嵌套结构实现无限层级学习。其核心创新在于连续谱记忆系统(CMS),该系统将记忆分解为不同更新频率的模块光谱:高频模块处理即时上下文,中频模块整合短期经验,低频模块沉淀长期知识。实验显示,这种分层记忆架构使模型在长序列处理中表现出色。
在语言建模基准测试中,Hope的困惑度较标准Transformer降低23%,在常识推理任务中准确率提升17%。特别在“大海捞针”长文本检索任务中,Hope成功从10万token序列中精准定位目标信息的概率达92%,远超Mamba2等对比模型的78%。这些性能提升源于CMS系统对记忆的动态优先级管理——模型能自动判断信息价值并调整存储策略。
嵌套学习带来的范式转变已催生两类实用技术。深度优化器通过将动量计算重构为联想记忆问题,使优化过程更适应噪声数据;连续谱记忆系统则突破Transformer的固定上下文限制,通过动态调整记忆模块的更新频率,实现真正意义上的持续学习。研究团队强调,这种统一视角为模型设计开辟了新维度,未来可延伸至多模态学习等领域。
尽管Hope等模型已展现潜力,研究者指出当前实现仅触及嵌套学习理论的表层。真正类人AI需要更精细的层级划分和生物可解释的更新机制。随着研究深入,这种将架构与优化融为一体的新范式,或将重新定义人工智能的能力边界。