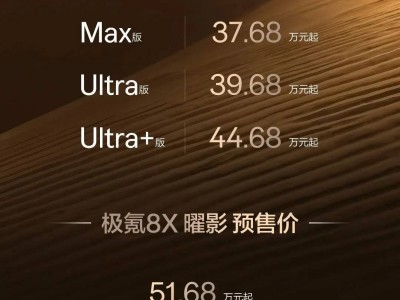
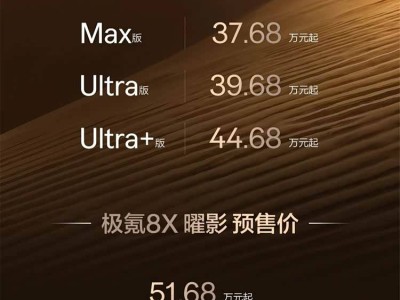
华为近日正式推出名为Flex:ai的创新型AI容器软件,该技术通过精细化算力管理方案,为人工智能应用场景提供更高效的资源分配模式。其核心突破在于实现了单张GPU或NPU算力卡的虚拟化切分,可将物理算力单元细分为多个独立虚拟资源,切分精度达到10%级别。这种技术架构使得单张算力卡能够同时承载多个AI任务,显著提升了硬件资源的利用率。
在集群管理层面,Flex:ai开发了动态算力聚合机制,能够自动识别并整合分布式节点中的闲置XPU资源。通过构建跨节点的共享算力池,该系统可根据实际需求灵活调配算力,有效解决传统模式下算力碎片化导致的资源浪费问题。这种弹性架构尤其适用于AI训练与推理场景中负载波动较大的情况,能够快速响应不同任务的算力需求。
技术实现方面,研发团队突破了传统虚拟化技术的性能损耗瓶颈,通过优化内存管理与通信协议,确保虚拟算力单元在保持独立性的同时,仍能接近物理硬件的原始性能。测试数据显示,在多任务并行场景下,系统整体吞吐量较传统方案提升3倍以上,任务切换延迟控制在毫秒级。
为推动技术生态建设,华为决定将Flex:ai的核心代码开源至魔擎开发者社区。此举旨在吸引全球开发者参与技术迭代,共同完善AI基础设施的标准化建设。开源版本已包含完整的API接口文档与开发工具链,支持主流深度学习框架的无缝对接,开发者可基于现有代码快速构建定制化解决方案。