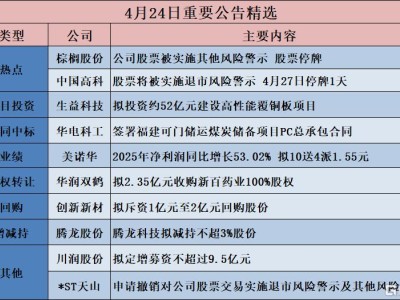
自动驾驶技术的安全性始终是制约其大规模应用的核心挑战。传统训练方法在部分场景中提升安全性能的同时,往往在其他场景引发性能退化,形成类似“按下葫芦浮起瓢”的困境。这种现象被业界称为“跷跷板效应”,其根源在于高价值安全事件的数据稀疏性导致模型训练效率低下,甚至出现过度拟合特定风险场景而忽视常规场景安全的情况。
清华大学与美国密西根大学联合研究团队提出“密集学习”新范式,通过聚焦高信息密度数据破解这一难题。该方法颠覆传统“海量数据训练”思路,转而构建智能筛选机制,仅对能显著提升安全性能的“关键数据”进行深度学习。研究团队将此类数据定义为“可避免事故场景”与“边缘风险事件”,例如险些发生碰撞的临界状态数据,这类数据虽占比不足1%,却包含90%以上的有效安全信息。
技术实现层面,研究团队设计出三层数据密化机制:首先通过策略梯度贡献度分析,自动识别高价值样本;其次采用自适应采样技术,确保关键数据在训练中的高频复现;最后通过方差缩减算法,在保持梯度估计无偏性的前提下,将训练方差降低两个数量级。这种创新方法使模型在复杂城市场景中的碰撞率下降98%,高速场景下降86.3%,实车测试中可避免事故率降低98.8%。
实验验证采用虚实融合测试平台,在密西根大学Mcity测试场构建包含2000个高风险场景的混合现实环境。研究团队开发的“AI安全教练”系统可实时监测32项安全指标,当预测到2秒内可能发生碰撞时自动接管控制。测试数据显示,搭载该系统的L4级自动驾驶车辆在城市场景中的碰撞频率从每百万公里1.44次降至0.14次,达到人类驾驶员安全水平的3倍以上。
与传统方法依赖事故数据训练不同,密集学习框架强调“成功经验”的积累。研究团队通过理论推导证明,单纯增加失败案例训练量会导致模型在常规场景的误判率上升27%,而聚焦可避免事故数据则能使整体安全性能提升15-20倍。这种数据筛选机制类似智能题库系统,自动过滤简单题与超难题,专注攻克“差一点就做对”的临界题目。
该成果已形成完整技术体系,包含从数据生成、筛选到训练的全流程解决方案。在nuPlan基准测试中,基于密集学习的模型使总碰撞数降低21.7%,其中自动驾驶系统责任事故减少29.2%。研究团队特别指出,该方法突破了传统强化学习的稀疏奖励瓶颈,为安全关键型AI系统训练提供了新范式。
技术落地层面,研究团队正与多家车企开展合作,将密集学习框架集成至量产车型。通过构建包含10亿级场景的虚拟测试库,结合实车数据闭环更新,预计可使自动驾驶系统迭代速度提升3-5个数量级。这项突破不仅为无人驾驶商业化扫清关键障碍,其核心算法还可迁移至医疗机器人、工业控制等安全敏感领域。