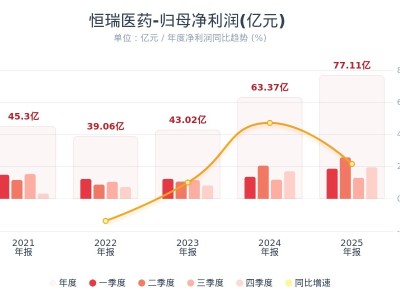
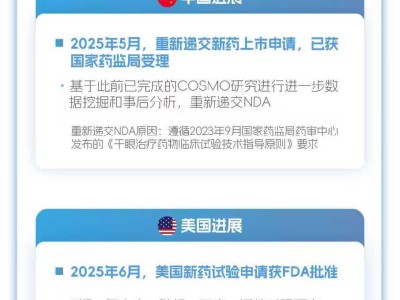
华为近期宣布了一项在人工智能领域的重大进展,通过其创新的“昇腾 + Pangu Ultra MoE”系统,成功实现了近万亿参数的大规模稀疏模型(MoE)的高效训练。这一壮举尤为引人注目之处在于,整个训练过程在没有依赖传统GPU加速的情况下完成,彰显了华为在自主可控算力及模型训练技术上的深厚积累。
在技术实现层面,华为研发团队对训练系统进行了全面优化,通过精细设计的并行策略与计算通信优化,极大提升了集群的训练效能。据华为发布的技术细节显示,在CloudMatrix384超节点平台上实施的多项技术创新,如创新的通信协议与负载均衡算法,近乎消除了大规模MoE训练中的专家并行通信开销,并确保了计算任务的均衡分配。
华为在提升单节点计算能力方面也取得了显著成果。通过深入优化训练算子的执行流程,华为不仅将微批处理规模扩大了一倍,还有效解决了算子调度中的效率瓶颈。这一技术革新意味着,在处理复杂计算任务时,华为的系统能够更充分地挖掘和利用现有硬件资源,实现更高的训练效率。
这一系列技术创新不仅标志着华为在MoE模型训练效率上的巨大飞跃,更为未来构建和应用更大规模的AI模型奠定了坚实的基础,预示着人工智能领域或将迎来新的变革与发展机遇。