近期,上海人工智能实验室携手清华大学及美国伊利诺伊大学香槟分校的研究团队,共同研发出了一种创新方法,用以解决大型语言模型在强化学习过程中的策略熵崩溃问题。这一突破性的进展,得益于Clip-Cov和KL-Cov两项技术的引入。
随着大型语言模型(LLMs)在逻辑推理能力上的显著提升,强化学习(RL)的应用场景得以大幅扩展,从原先的单一任务扩展到更为复杂多变的环境。这一转变,无疑为模型赋予了更强的泛化能力和逻辑推理能力。然而,强化学习的高计算资源需求以及策略熵下降的问题,成为了制约其进一步发展的关键因素。
策略熵,作为衡量模型在利用已知策略和探索新策略之间平衡状态的指标,其过低会导致模型陷入对已有策略的过度依赖,从而失去对新策略的探索能力。这种探索与利用之间的权衡,正是强化学习的基础所在。因此,如何有效控制策略熵,成为了强化学习训练过程中的一大难题。
为解决这一问题,研究团队提出了一个全新的经验公式:R = −a exp H + b,其中R代表下游任务的表现,H为策略熵,a和b为拟合系数。该公式揭示了策略性能与熵值之间的微妙关系,并指出熵耗尽是导致性能瓶颈的主要原因。在此基础上,团队进一步分析了熵的动态变化,发现其受到动作概率与logits变化协方差的影响。
针对这一发现,团队创新性地提出了Clip-Cov和KL-Cov两项技术。前者通过裁剪高协方差token来维持熵水平,后者则通过施加KL惩罚来达到同样的效果。实验结果显示,这两项技术在Qwen2.5模型和DAPOMATH数据集上均取得了显著成效,特别是在AIME24和AIME25等高难度基准测试中,32B模型的性能提升高达15.0%。
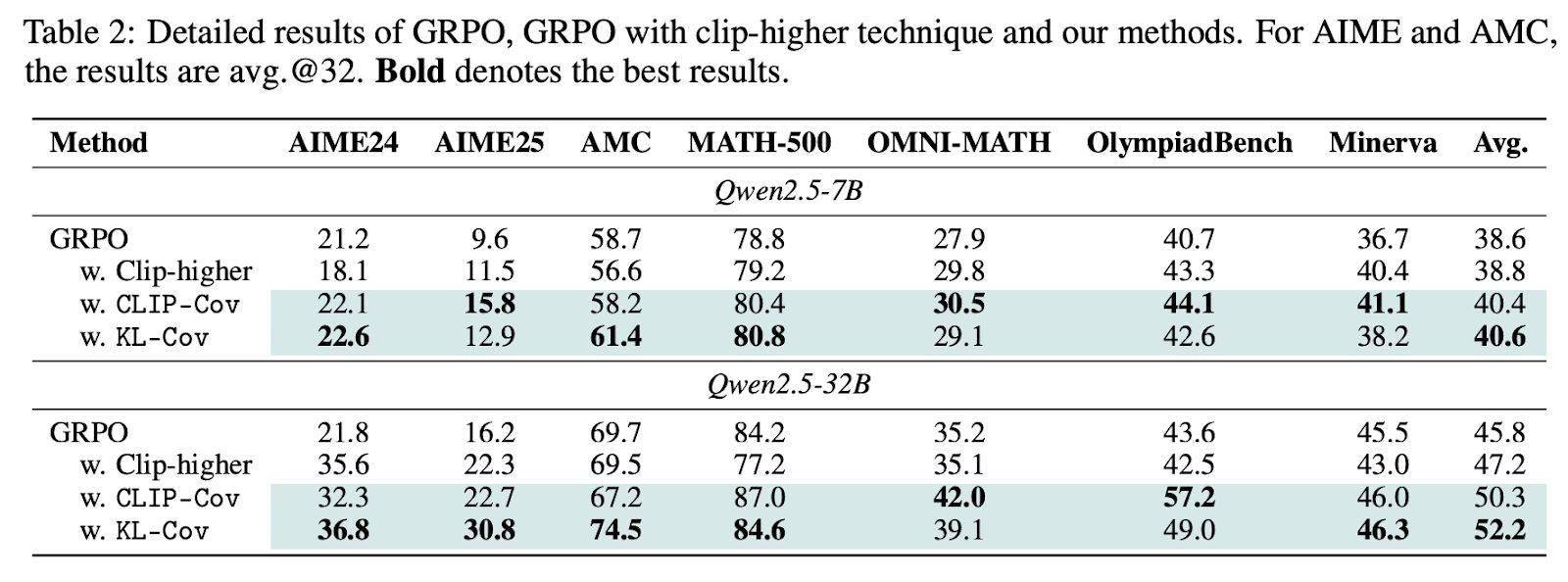
为进一步验证这两项技术的有效性,研究团队还在包括Qwen2.5、Mistral、LLaMA和DeepSeek在内的11个开源模型上进行了测试,这些模型的参数规模从0.5B到32B不等,涵盖了数学和编程任务的8个公开基准测试。实验结果表明,Clip-Cov和KL-Cov技术均能在不同模型上维持更高的熵水平,从而显著提升模型的性能。
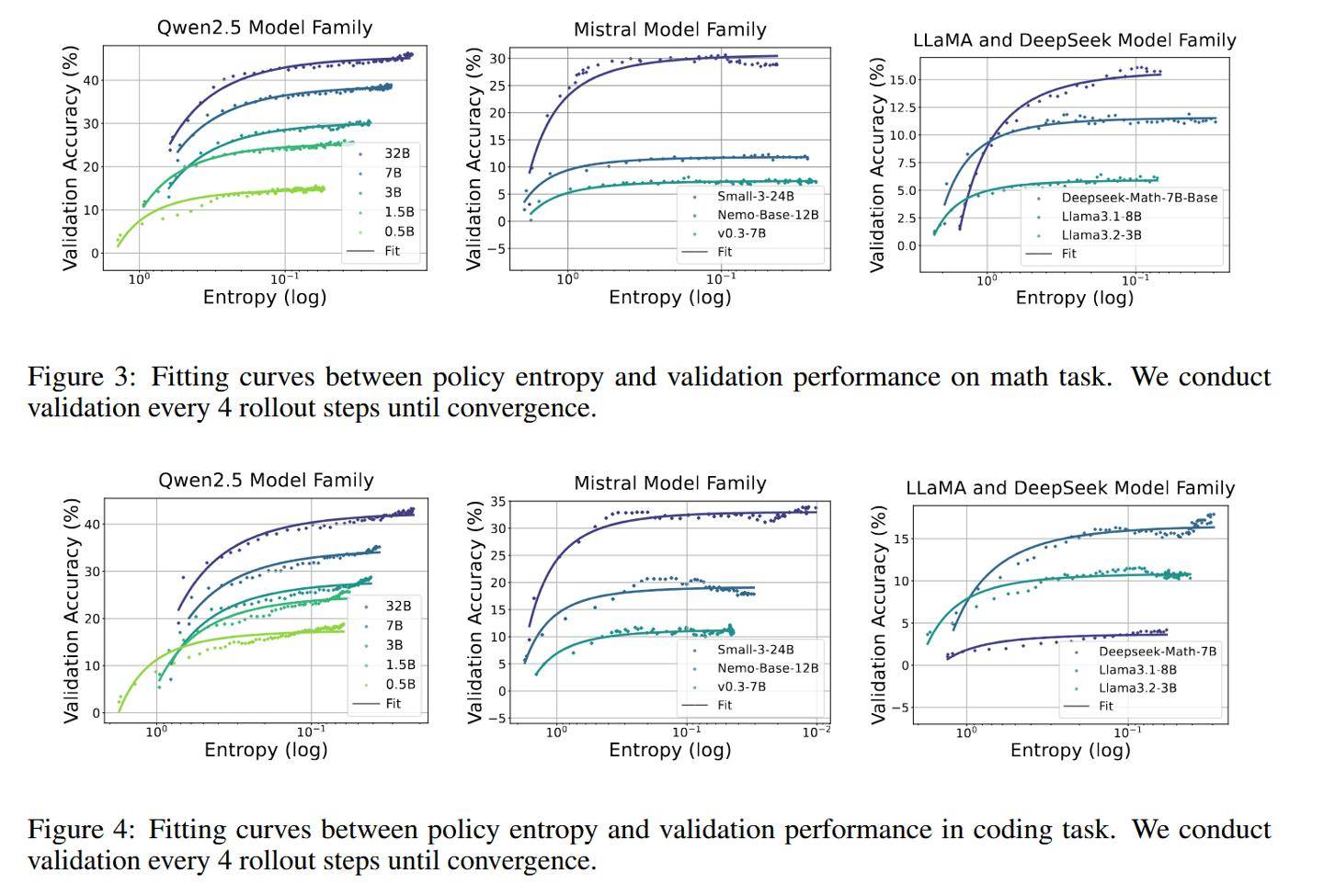
在训练过程中,研究团队采用了veRL框架和零样本设置,并结合了GRPO、REINFORCE++等算法来优化策略性能。实验结果显示,KL-Cov方法在基线熵值趋于平稳时,仍能保持10倍以上的熵值,充分证明了其有效性。
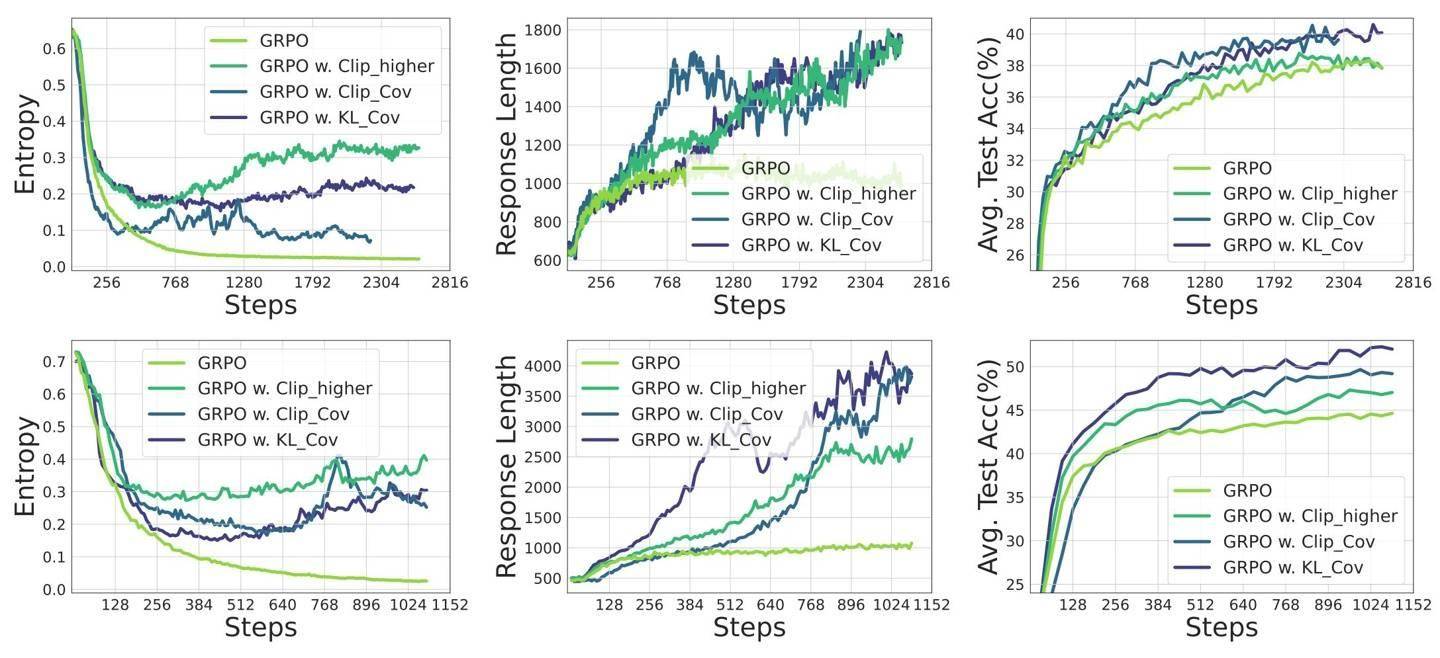
此次研究不仅成功解决了策略熵崩溃问题,还为强化学习在语言模型中的扩展提供了坚实的理论支持。研究团队强调,熵动态是制约性能提升的关键瓶颈,未来需要继续探索更为有效的熵管理策略,以推动语言模型的智能化发展。