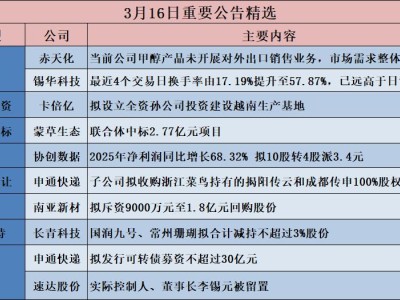
在人工智能领域,一项由苹果科研团队发起的研究揭示了大型推理模型(LRM)在应对复杂任务时的局限性,为这一热门研究方向带来了意外的冷静思考。
研究聚焦于Claude3.7Thinking和Deepseek-R1等推理模型,这些模型旨在通过模拟思维过程来提升问题解决能力。然而,在实际测试中,它们的表现却令人失望。研究选取了四种经典的逻辑谜题——汉诺塔、跳棋、渡河和积木世界,这些谜题因能够精确调控任务难度,而被视为评估语言模型推理能力的理想工具。
测试结果显示,在简单任务上,传统的标准大型语言模型(LLM)表现得更为准确且高效。随着任务复杂度的提升,虽然推理模型的表现略有改善,但最终还是在高复杂度任务面前全面崩溃。更令人惊讶的是,当面对最复杂的任务时,这些模型不仅准确率骤降至零,而且使用的推理标记(tokens)数量也显著减少,表明它们在“思考”的意愿和能力上都出现了衰退。
研究团队进一步分析了模型在不同复杂度下的推理轨迹,发现两种典型的失败模式:一种是“过度思考”,即在简单问题中,模型找到正确答案后仍持续生成错误的备选方案;另一种是“思考崩溃”,在高复杂度问题中,模型的推理过程突然中断,甚至无法尝试生成任何解决方案。
一直以来,推理模型通过引入“思路链”和“自我反思”等机制,被视为通往通用人工智能(AGI)的关键一步。然而,苹果的研究指出,这些机制在扩展性上存在根本缺陷。当前的推理模型无法制定出具有通用性的策略,其所谓的“思考”更多是基于统计的生成,而非真正的逻辑演绎。
研究还发现,模型在不同谜题上的表现与训练数据密切相关。例如,在训练数据中频繁出现的“汉诺塔”任务,其准确率普遍高于复杂度相似但数据较少的“渡河”任务。这进一步凸显了当前模型对训练数据分布的严重依赖。
苹果研究人员指出,当前推理模型的“思维能力”存在与问题复杂度相对的不对称扩展性问题,在结构上无法支撑高阶任务的解决。他们呼吁,应对推理模型的核心设计原则进行重新思考,以克服这些根本性的技术挑战。
这一发现对人工智能行业产生了深远的影响。随着AI模型规模扩展的收益逐渐趋于饱和,推理能力被视为推动AI迈向下一阶段革命的关键。包括OpenAI在内的多家头部企业,都在这一方向上投入了大量资源。然而,苹果的研究提醒我们,在通往真正“理解”和“推理”的道路上,AI仍然面临着严峻的技术障碍。