在AI加速芯片市场的白热化竞争中,AMD近期震撼发布了Instinct MI350系列加速器,包括MI350X与高性能液冷版MI355X,这一举动标志着AMD正式向行业领头羊NVIDIA发起正面挑战,尤其是在AI训练和推理领域。
与之前的MI300系列相比,MI350系列不仅在架构层面实现了迭代升级,更明确了其市场定位,专注于满足AI训练和推理的严苛需求。两款新品均采用了先进的3nm工艺,并配备了高达288GB的HBM3E高带宽内存,延续了AMD一贯的高规格配置策略。

作为旗舰型号的MI355X,功耗高达1400W,专为高密度计算环境设计,搭配液冷系统,确保了卓越的性能输出。在实际性能对比测试中,MI355X在主流大模型推理任务中展现出相对于MI300X三倍以上的性能提升,这一跨代式的性能飞跃,无疑彰显了架构层面的重大优化。
在与NVIDIA Blackwell平台的较量中,AMD虽然尚未占据绝对的市场主导地位,但凭借相似的计算性能、更大的显存配置以及更低的预期成本,在特定客户需求下展现出了强劲的竞争力。AMD此次不仅强调单卡性能,更重视整体系统架构的优化以及机架规模的部署能力。

MI350系列在规格设计上兼容UBB 8 GPU模块,这意味着它们可以无缝集成到现有的高性能AI计算平台中,包括NVIDIA HGX类系统,这种平台级的兼容性大大降低了部署壁垒,为AMD打入更多数据中心和云厂商体系铺平了道路。
AMD此次并未过分强调峰值性能的领先性,而是将重点放在了综合系统效能、机架级资源配置以及开放标准支持上。通过超级以太网联盟(UEC)和UALink等互联协议,MI350系列支持64至128颗GPU的横向扩展,能够在单个机架中构建起高达36TB的共享显存资源池,展示了一个具有延展性的AI基础设施组件。

MI350系列的发布,不仅是AMD技术更新的一次展示,更是其面向AI产业趋势调整战略重心的体现。从架构设计到市场策略,AMD正在逐步淡化过去以高性能计算为主的产品定位,将更多资源投入到AI加速领域,尤其是大模型的训练和推理。
在技术路线上,MI350系列延续了MI300时代的模块化封装与堆叠设计思路,但在芯粒数量、互联方式、缓存架构以及张量计算能力等方面均实现了优化。特别是在FP4与FP6浮点计算性能上的提升,成为AMD本代产品的核心技术亮点,这些精度的粒度更适配推理场景下对功耗与计算资源的综合要求。
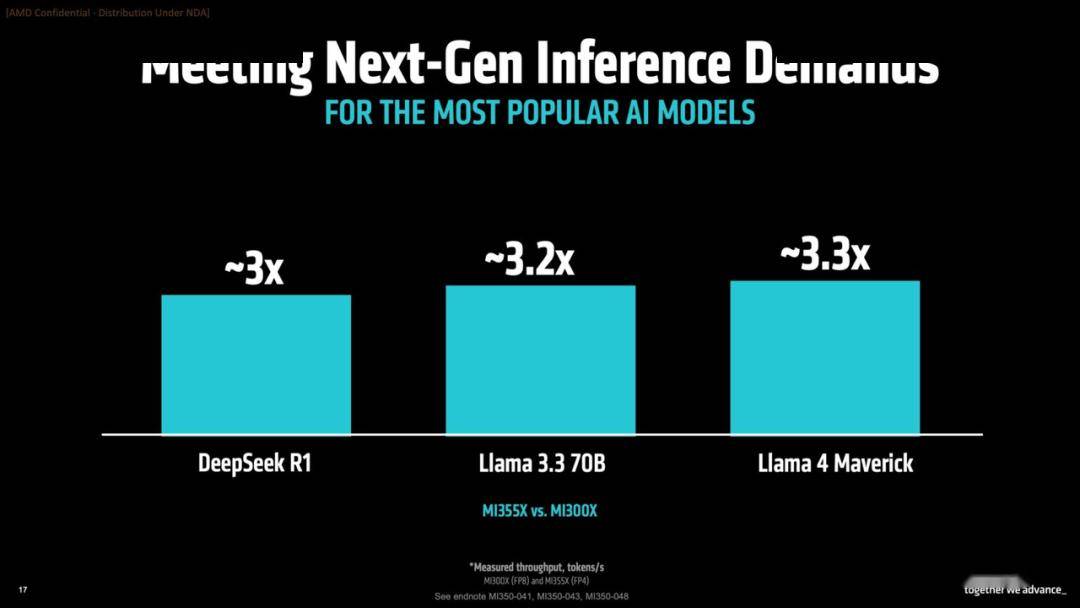
MI350系列面向AI训练和推理两个核心场景的定位更加清晰。在训练方面,得益于更大的HBM带宽与GPU间互联性能,MI355X在处理超大参数模型时具有显著优势;而在推理环节,FP4的高密度计算能力可以大幅提升每瓦性能,进而降低整体部署成本。
AMD通过精确的市场定位与资源匹配,走出了一条与NVIDIA不同、更具工程实用性的平衡路径。AMD在此次发布会中强调了“基于价值的销售”模式,即以系统总效能与总成本的均衡来争取客户,而非单纯追求性能参数的绝对领先。这一策略背后,是对AI基础设施建设日益复杂化、资源分布多样化趋势的深刻理解。

与NVIDIA更封闭的生态构建策略不同,AMD选择了开放标准作为其生态扩展的支点。通过支持开放式互联标准、构建可替换模块、兼容主流平台等方式,AMD增强了产品的可适配性与可持续性,降低了用户的技术锁定风险。在未来AI基础设施构建过程中,市场需要的不仅是性能强大的GPU,更是一个可持续、灵活且经济高效的系统解决方案。