WAVES新浪潮2025大会在杭州良渚文化艺术中心隆重举行,此次盛会以“新纪元”为主题,汇聚了创投领域的众多精英,共同探索中国创投市场的新篇章。大会期间,创投领域的顶级投资人、新锐企业创始人以及科技、创新、商业界的学者与创作者齐聚一堂,就AI技术革新、全球化浪潮与价值重估等前沿议题展开了深入探讨。
6月12日上午,红杉中国的投资人公元在创业者会场发表了一场引人深思的独立演讲,主题为“AI下半场:如何定义‘好问题’?”。公元的演讲围绕红杉中国最新推出的xbench基准测试展开,分享了背后的思考与探索。
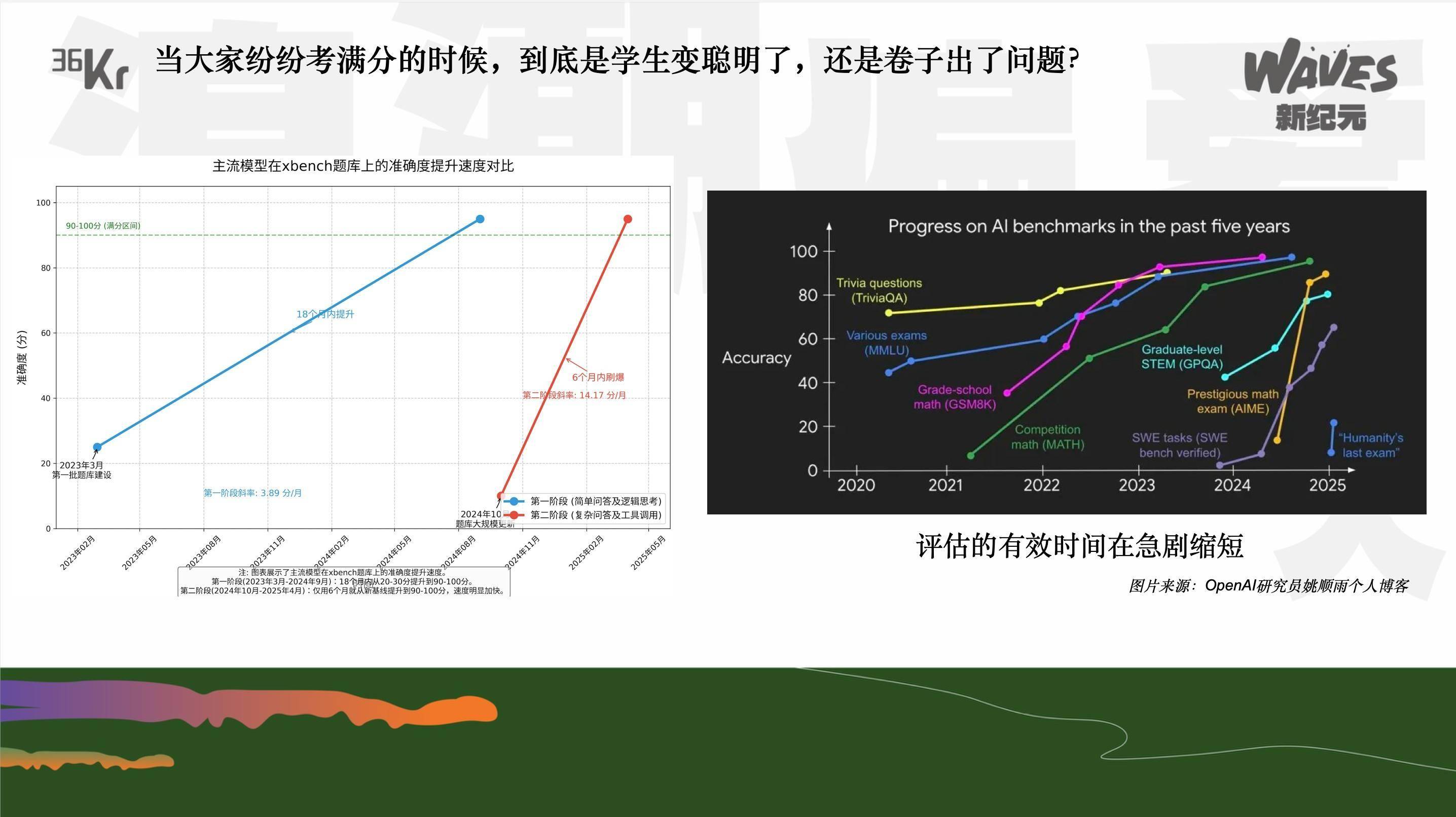
公元首先展示了两组图表,揭示了AI上半场的一个显著问题:每当新的数据集和测试标准出现,大模型总能迅速达到顶尖水平(SOTA),随后便会有新的基准测试推出,再次促使大模型达到SOTA,形成了一个无限循环。这种趋势引发了深刻思考:当大模型都考满分时,是模型真正变聪明了,还是测试标准本身存在问题?
公元回顾了红杉中国在过去两年多时间里,对基准测试的三次迭代过程。从ChatGPT初现端倪时,红杉便意识到大模型可能是十年一遇的大浪潮,因此着手建立内部标准和工具,以实时观测模型发展,更好地指导投资。最初的基准测试包含简单的逻辑题和数学题,但很快就被大模型轻松破解。随着OpenAI等模型的进步,红杉不断升级测试难度,但大模型依然能够迅速适应,这促使红杉开始反思测试标准的有效性。

在第三次迭代时,红杉开始深入探索如何在AI下半场提出“好问题”。公元指出,过去的研究者往往陷入了一种惯性思维,即不断提高问题难度以测试模型能力。然而,这种惯性思维真的正确吗?模型越来越聪明,真的等同于具备投资价值吗?红杉开始反思模型能力与经济效用之间的关系,并致力于建立一套既能评估模型智能水平,又能评估其经济效用的标准。
公元进一步阐述了红杉在第三次迭代中的思考方向。他提到,AI模型的能力可以分为两部分:一部分是AGI track,评估模型的通用智能水平;另一部分是Profession-aligned track,评估模型在现实世界中的经济效用。例如,在search能力上,AGI track可能关注模型在复杂搜索任务上的表现,而Profession-aligned track则关注模型在猎头、市场运营等具体职业岗位上的应用效果。

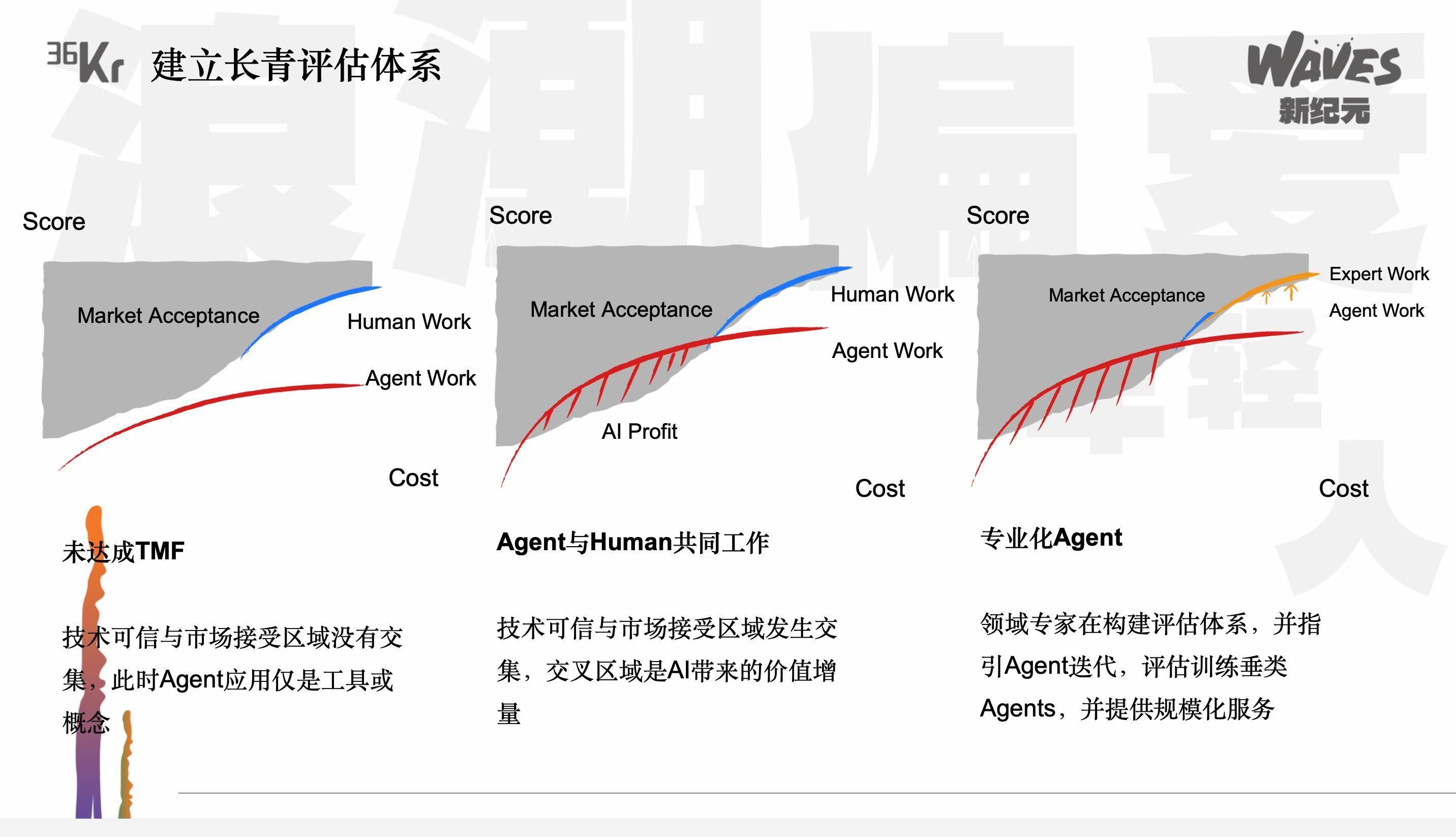
红杉还致力于建立一套长青的评价体系,以解决不同时间维度和不同数据集上模型能力的比较问题。公元介绍了红杉采用IRT方法进行的数学建模和回归测试,通过调整分数曲线,使其能够真实反映模型能力的单调递增趋势。这一体系对于评估模型和Agent的长期发展具有重要意义。
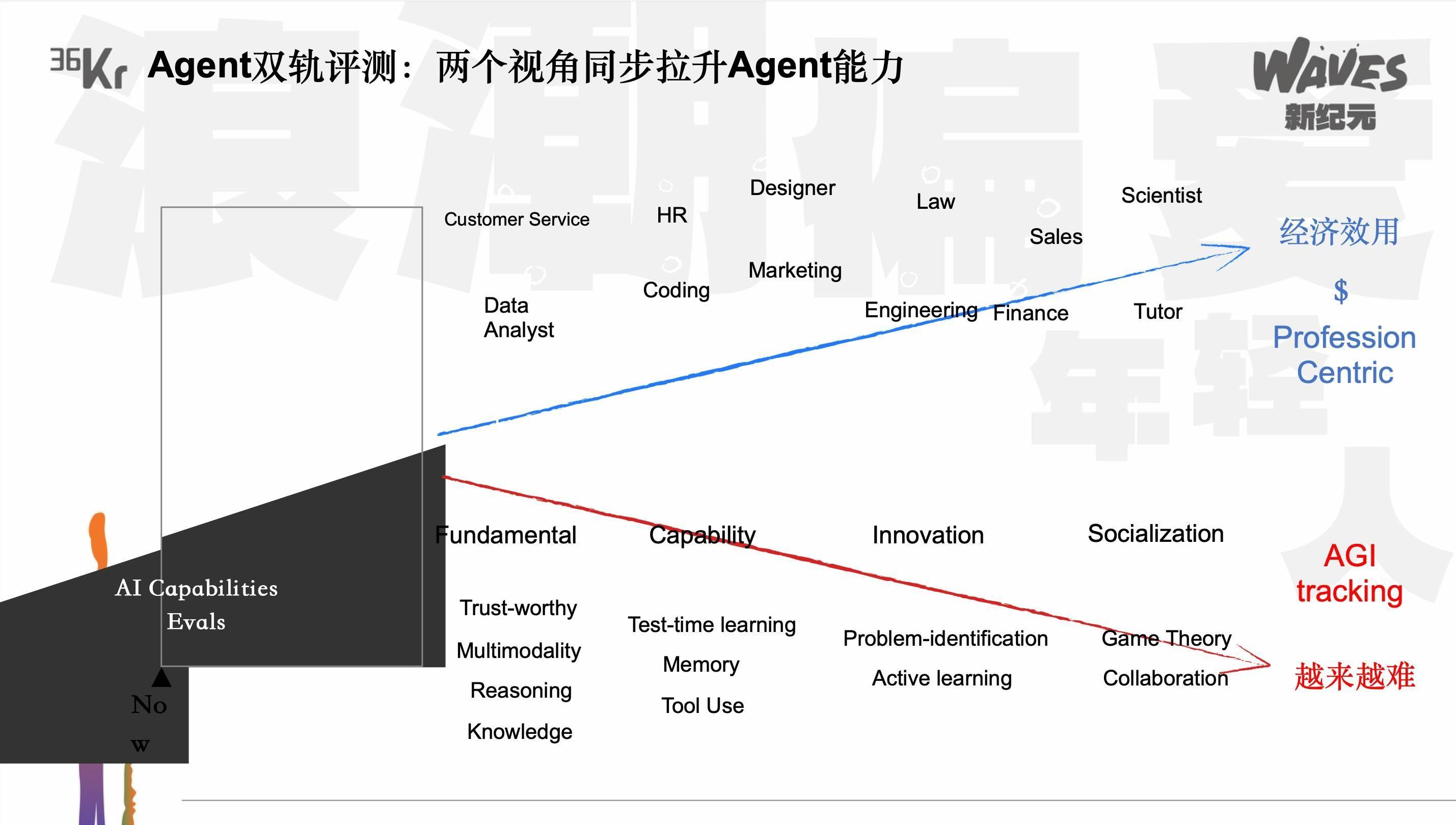
在演讲的最后部分,公元提出了TMF(Technology-Match-Future)的概念,强调在评估模型和Agent能力时,需要关注其无限逼近人的能力,并根据能力发展阶段判断投资拐点和切入赛道的时机。他展示了xbench第一期的评估结果,并呼吁社区共建一套Agent的评估标准,以促进整个行业的发展。
公元的演讲引发了与会者的热烈讨论和思考,为WAVES新浪潮2025大会增添了一抹亮色。此次大会不仅是中国创投市场新纪元的起点,更是AI技术革新与价值重估的重要里程碑。