在人工智能领域,一个崭新的转折点正在悄然到来:AI正从“执行任务”迈向“理解并行动”的阶段。近期,谷歌DeepMind宣布了一个重要进展——Gemini Robotics On-Device,这是首个专为机器人设计的视觉-语言-动作(VLA)模型,无需网络连接,即可在机器人设备上离线运行。
这一突破性的VLA模型,展现了强大的视觉识别、语义理解和行为执行能力。在测试中,它能够理解自然语言指令,完成诸如拉开拉链、折叠衣物等高难度动作。这一技术不仅革新了机器人智能的范畴,还为辅助驾驶的智能化升级开辟了新路径。
VLA模型的问世,标志着从视觉-语言模型(VLM)到多模态机器学习模型的演进。相较于传统模型,VLA将视觉、语言和动作能力整合于单一模型中,实现了从输入到动作的端到端映射。这种整合赋予了模型卓越的3D空间理解、逻辑推理和行为生成能力,使自动驾驶系统能够更智能地感知、思考和适应环境。
在自动驾驶领域,感知技术通常由多种传感器负责,但传统方案存在模块间误差累积、规则设计复杂等问题。VLA模型通过统一的神经网络,从多模态输入中学习最优控制策略,简化了系统架构,提高了数据利用效率。它不仅理解人类指令,还能生成可解释的决策过程,将多模态信息转化为具体的驾驶操作指令。
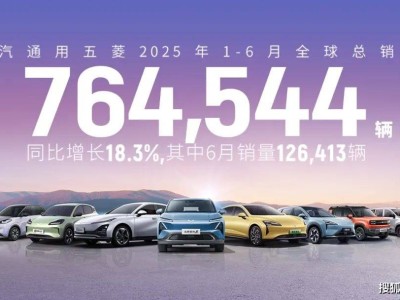
汽车行业正经历一场智驾技术的激烈竞争。比亚迪、吉利、奇瑞等主流车企纷纷推出智能辅助驾驶计划,标志着“得智驾者得天下”的时代已经到来。自2023年起,BEV、端到端技术浪潮席卷智驾行业,车企们逐步将AI神经网络融入感知、规划、控制等环节,以提升智驾能力。
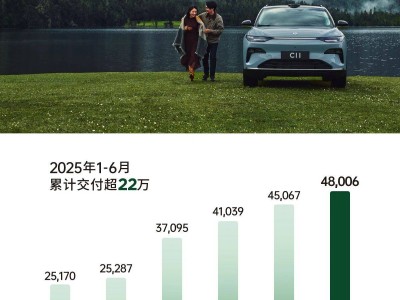
VLA模型在此背景下显得尤为重要。它拥有更高的场景推理与泛化能力,对智能辅助驾驶技术的演进具有重大意义。理想汽车、小鹏汽车等车企正积极探索VLA技术的应用,以提升自动驾驶系统的性能上限。例如,理想汽车发布了新一代自动驾驶架构MindVLA,计划于2026年量产应用,通过整合空间智能、语言智能和行为智能,赋予自动驾驶系统更强大的能力。
在VLA模型之前,“端到端+VLM”一直是智驾行业的主流技术方案。然而,尽管这一方案显著提升了智驾水平,但仍面临诸多挑战,如端到端与VLM的联合训练困难、3D空间理解不足等问题。VLA模型通过统一的大模型架构,将感知、决策、执行无缝串联,形成闭环,同步提高了智驾的上限和下限。
VLA模型的工作原理包括视觉感知、语言理解与决策生成、动作控制三个阶段。视觉编码器提取高层次视觉特征,语言编码器处理自然语言输入,跨模态融合模块整合视觉和语言特征,动作生成模块根据融合信息生成控制指令。这一流程使得VLA模型能够像人类驾驶员一样思考和判断,在面对复杂交通规则和特殊场景时做出合理决策。
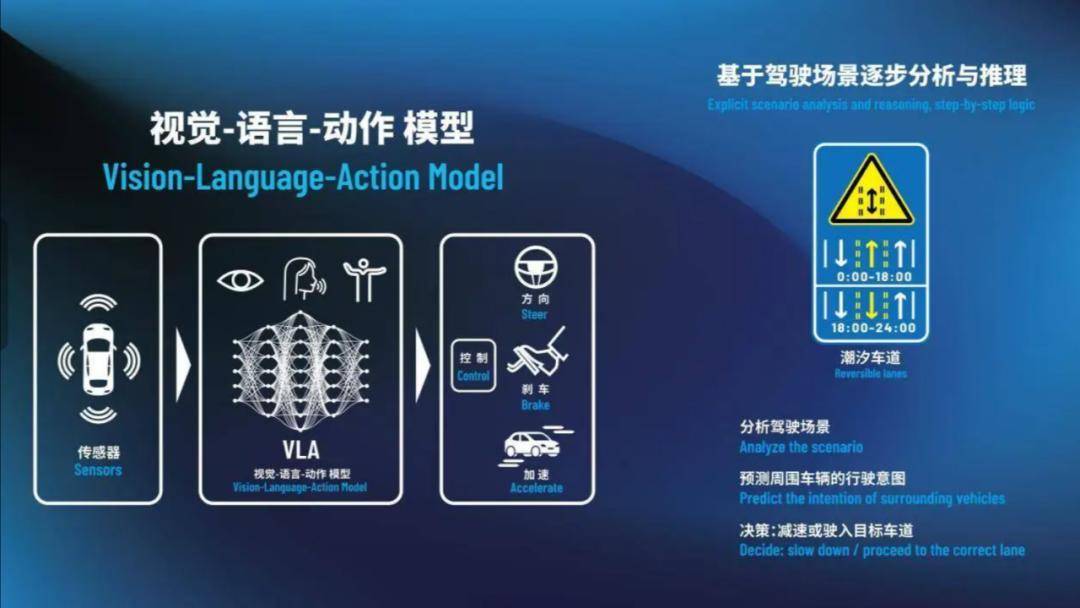
然而,VLA技术的应用仍面临两大难点:车端算力不足和数据与信息深度融合的挑战。为解决这些问题,车企们正在探索多种技术路径,如引入可解释性模块、利用Diffusion模型优化轨迹生成、结合传统规则引擎等,以提高系统的安全性和鲁棒性。
随着大模型技术、边缘计算和车载硬件的不断进步,VLA模型有望在智能辅助驾驶领域发挥更加核心的作用。它不仅能为城市复杂道路提供更智能的驾驶方案,还可扩展至车队协同、远程遥控及人机交互等多种应用场景,重塑智能辅助驾驶产业的格局。