华为近日宣布了一项重大举措,针对超大规模MoE(混合专家)模型的推理问题,开源了其名为Omni-Infer的新项目。这一行动无疑为众多企业用户和开发者带来了福音。
Omni-Infer项目包含了推理框架与推理加速套件两大核心部分。推理框架方面,Omni-Infer与业内的主流开源大模型推理框架如vLLM等实现了完美兼容,这类似于不同品牌的组件能够无缝集成在同一系统中。同时,Omni-Infer的功能还在不断拓展,旨在为昇腾硬件平台上的大模型推理提供更强大的支持。
值得注意的是,Omni-Infer与vLLM、SGLang等主流框架是解耦的,用户可以独立安装,这大大降低了软件版本维护的成本。用户只需关注vLLM等框架的主版本,即可享受Omni-Infer带来的便利。
而Omni-Infer的推理加速套件则更像是一位企业级的“智能调度员”。它拥有智能调度系统,能够合理安排任务,支持大规模分布式部署,确保任务处理的低延迟和高效率。同时,它还是一个精准的“负载平衡器”,针对不同长度的任务序列,在预填充和解码阶段都做了优化,以实现最大吞吐量和低延迟。
对于MoE模型来说,Omni-Infer更是其“专属搭档”。它支持多种配置,如EP144/EP288等,让混合专家模型能够高效协作。Omni-Infer还具备分层非均匀冗余和近实时动态专家放置功能,智能地分配资源,确保资源的充分利用。
为了让AI推理更快更稳,Omni-Infer还专门为LLM、MLLM和MoE等模型优化了注意力机制。这一优化让模型在处理信息时更加聚焦和高效,提升了性能和可扩展性。
体验Omni-Infer也并不复杂。首先,它目前仅支持CloudMatrix384推理卡和特定版本的Linux操作系统。安装方面,用户可以通过Docker镜像方式进行安装,只需运行一条命令即可获取预先集成所需的CANN及Torch-NPU依赖包,同时内置可直接运行的Omni-Infer与vLLM工具包。
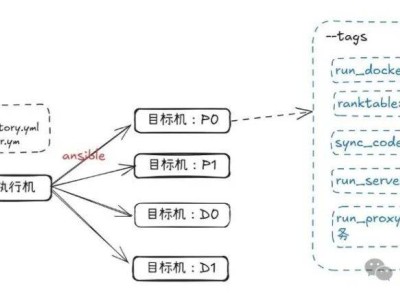
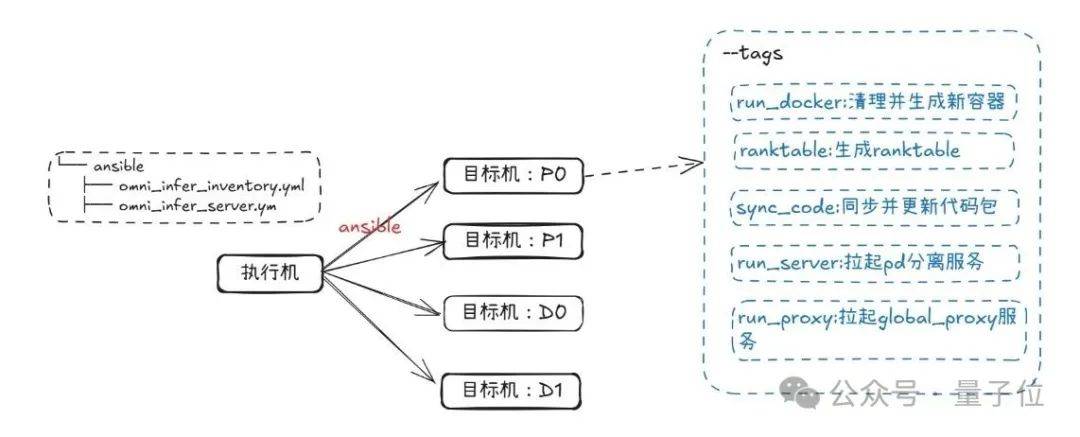
以PD分离自动化部署为例,用户只需按照文档教程,通过少量代码和步骤即可完成安装和部署。整个过程简单快捷,让AI推理变得更加高效。
除了技术上的开源,华为还为Omni-Infer建立了专业的开源社区。社区仓库中包含了社区治理、会议、活动、生态合作、代码规范、设计文档等全面信息,让开发者能够深入参与到社区发展中。同时,Omni-Infer社区采用了开放的治理机制,提供公正透明的讨论与决策环境。
Omni-Infer社区采取了“主动适配”的生态合作模式,积极拥抱国内正在成长的人工智能开源项目,实现生态的多方共赢。作为与业界主流开源基金会保持紧密合作关系的社区团队,Omni-infer的首个活动就将参与OpenInfra基金会在苏州的Meetup,为开发者提供了交流与学习的机会。
对于感兴趣的开发者和小伙伴来说,Omni-Infer的技术报告、可分析代码包以及更多相关信息已经全面开放,大家可以自行获取并参与到这一开源项目中来。