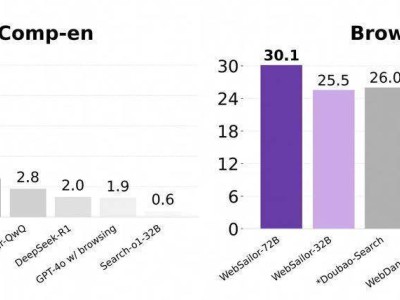
随着人工智能技术的飞速发展,一类全新的自主智能体正逐渐崭露头角,它们的核心驱动力是近年来取得突破性进展的大型语言模型(LLMs)。这些智能体不仅能够感知环境、进行复杂推理,还能在无需人类持续监督的情况下,通过调用各种工具执行多步骤任务,形成闭环反馈机制。这一转变标志着AI技术从静态预测模型向主动、具身智能体的重大跨越。
与传统AI系统相比,基于LLMs的智能体拥有更为广阔的行动空间和更强的适应性。它们能够阅读动态上下文、即兴学会新工具,并在运行时调整计划,追求既定目标。这种灵活性使得LLMs智能体在软件编程、网页自动化、个人助理乃至机器人控制等领域展现出巨大潜力,被视为通用人工智能发展的重要里程碑。
然而,随着智能体自主性的增强,一系列前所未有的安全风险也随之浮现。由于智能体能够执行具有真实后果的行为,如执行代码、修改数据库或调用API,因此系统故障和对抗性攻击的风险被大幅放大。这些风险源于智能体的核心特性:多步推理、动态工具使用和面向环境的适应性,这些特性扩展了攻击面,使得智能体在多个系统层级上均可能遭受攻击。
为了应对这些挑战,研究者们近年来提出了多种防御策略,包括输入净化、记忆生命周期控制、受限决策制定、结构化工具调用以及内省式反思机制等。然而,这些策略大多孤立实施,缺乏对跨模块、跨时间维度涌现性威胁的系统性响应能力。因此,迫切需要一种更为统一、前瞻性的安全保障框架。

在此背景下,反思性风险感知智能体架构(R2A2)应运而生。这一统一的认知框架基于受限马尔可夫决策过程(CMDPs),融合了风险感知世界建模、元策略适应以及奖励–风险联合优化机制。R2A2旨在智能体的决策循环中实现系统化、前瞻性的安全保障,从而有效应对自主性增强带来的安全挑战。
R2A2架构的提出,不仅为智能体的安全性设计提供了理论蓝图,也为下一代AI智能体的发展指明了方向。通过将安全性作为核心设计原则,R2A2有望在确保智能体可靠追求有益目标、配合人类监督的同时,降低目标错配带来的风险。这对于推动人工智能技术的健康、可持续发展具有重要意义。
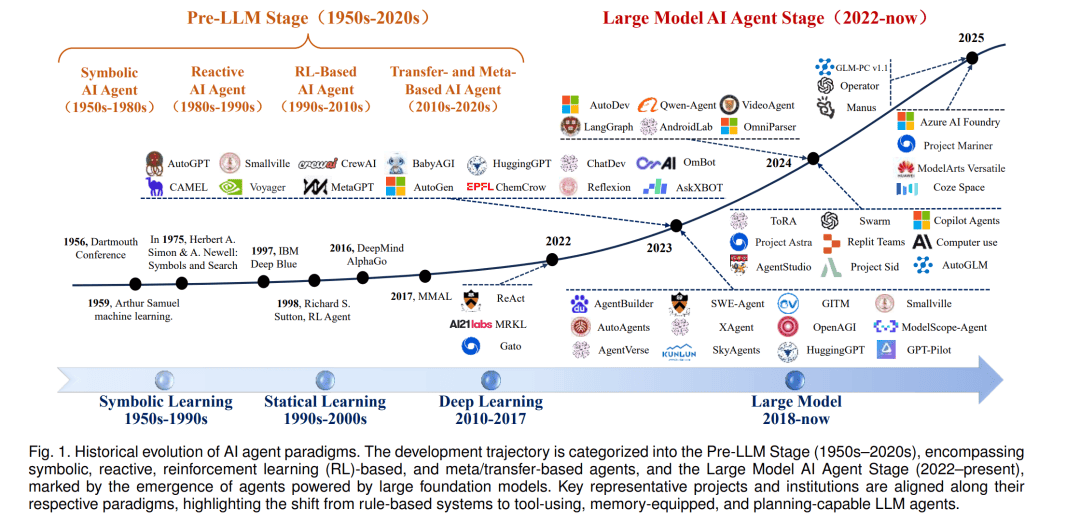
值得注意的是,尽管基于LLMs的智能体带来了前所未有的变革潜力,但其安全性问题同样不容忽视。未来,随着技术的不断进步和应用场景的不断拓展,如何进一步完善智能体的安全保障机制,将成为AI领域亟待解决的关键问题之一。同时,加强跨学科合作、推动技术创新与伦理规范的协同发展,也将是确保人工智能技术健康发展的重要保障。