
今天凌晨,OpenAI发布了最新技术论文思维链(CoT)监控,用来监督AI Agent等AI系统使得它们的自主性更强。
有网友表示,针对生产环境中的AI Agent而言,这一点至关重要。几个月来,我们一直在运行Mario和Erika两款AI智能体,而黑箱问题确实存在。例如,当Mario做出一个有问题的销售决策时,我需要看到它的推理过程而不仅仅是输出结果。
思维链可监控性的重要意义是:调试智能体的故障;合规审计尤其是在金融、医疗领域与对AI决策持怀疑态度的利益相关者建立信任。
所以,OpenAI发布这个研究非常明智,随着智能体的自主性越来越强,可解释性将成为一项业务要求,而不仅仅是一个可有可无的功能。

思维链监控似乎是让人类能够理解AI认知过程的关键一步,尤其是如果它能成为智能体的标准配置的话。透明度与可解释性相结合,就能产生信任。

思维链监控不仅仅是一项技术升级,更是构建安全且透明的AI的蓝图。随着智能体不断发展,我们需要能够洞察它们的推理过程。很高兴看到OpenAI在这一前沿领域处于领先地位。
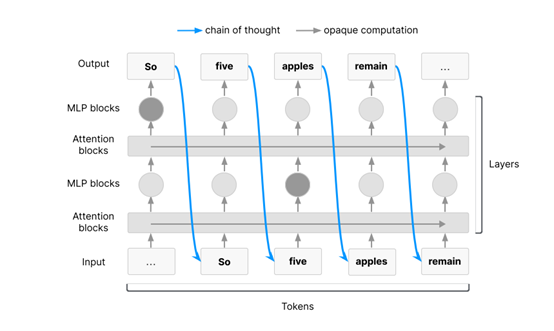
为什么需要监控CoT
在某些复杂的任务中,AI必须通过链式思考来完成推理过程。这是因为这些任务需要大量的序列化推理步骤,而这些步骤必须通过链式思考来实现。
以Transformer架构为例,这种架构是目前大多数前沿AI模型的基础,它通过自回归采样逐步生成输出。在Transformer架构中,任何足够长的序列化推理过程都必须通过链式思考来完成。
当AI需要完成复杂的任务,如多步规划或高级推理时,它必须利用链式思考作为工作记忆。例如,用AI Agent解决一个复杂的数学问题或进行多步规划时,它需要将中间结果存储在链式思考中,以便后续步骤可以使用这些结果。这种必要性确保了在处理足够复杂的任务时,AI的链式思考中必然包含其推理过程的一部分信息。换句话说,对于这些任务,AI无法在不通过链式思考的情况下完成推理。
仅仅存在必要性并不足以保证链式思考的可监控性。虽然链式思考中包含推理过程的信息,但这些信息能以一种人类难以理解的方式呈现。例如,AI可能会使用一些特殊的符号或编码来表示其推理过程,而这些符号或编码可能无法被人类直接解读。因此,链式思考的可监控性还依赖于AI是否以人类可理解的方式展示其推理过程。

即使对于不需要链式思考的任务,AI也可能倾向于通过自然语言展示其推理过程。这种倾向性虽然不如必要性那样可靠,但在某些情况下仍然可以提供有用的信息。
在训练过程中,AI通常被优化以产生自然语言输出,这意味着它们可能会自然地展示其推理过程。例如,当AI被训练以回答问题时,它会通过逐步展示其推理过程来生成答案。这种倾向性使得研究人员可以通过监控链式思考来获取AI的内部信息。
有效CoT监控方法
OpenAI在研究论文中分享了一些有效的CoT监控方法,可以开发用于测试CoT可读性的工具。例如,利用另一个大型语言模型来评估CoT的清晰度和连贯性;也可以进行潜在推理能力的评估,这将测试大型语言模型在不外化推理过程的情况下进行推理的能力。
还可以开发用于测量CoT因果相关性的方法,例如,通过扰动CoT并检查其是否影响最终输出来评估CoT的重要性。也可以进行端到端的监控有效性评估,直接测量CoT监控在检测AI智能体行为异常方面的有效性。
需要注意的是在当前的AI模型训练中,优化目标通常是让模型产生正确的输出,而不是优化其推理过程。这种训练方式可能会导致模型的CoT与最终输出之间的关系变得模糊,从而降低监控的有效性。
例如,直接监督CoT的训练方法可能会使模型的CoT更短、更符合逻辑,或者避免包含不当内容。虽然这些优化目标可能会提高模型的对齐性,但同时也可能会使CoT不再真实反映模型的决策过程。
因此,需要研究这些优化压力对CoT监控的影响,以便在提高模型对齐性和保持CoT监控有效性之间找到平衡。
当前的CoT监控方法大多依赖于对模型输出的直接分析,但这种方法可能无法捕捉到模型内部的复杂推理过程。因此,需要开发更先进的监控技术,这些技术可以深入到模型的内部结构,以更全面地理解模型的决策过程。
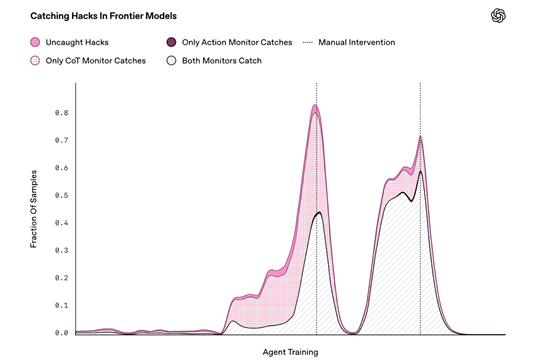
例如,可以开发基于推理模型的监控器,这些监控器可以利用模型内部的推理过程来检测潜在的恶意行为。还可以开发允许监控器在测试时进行计算的方法,例如通过让监控器向模型提问来获取更多信息。这种方法不仅可以提高监控的有效性,还可以增强监控系统的鲁棒性。
对抗性训练也是提高监控系统鲁棒性的一种有效方法。通过让监控系统与模型进行对抗,模型试图隐藏其恶意行为,而监控系统则试图发现这些行为。通过这种方式,监控系统可以不断学习和改进,以更好地应对模型的隐藏行为。

















