闻乐 鱼羊 发自 凹非寺量子位 | 公众号 QbitAI
编程Agent王座,国产开源模型拿下了!
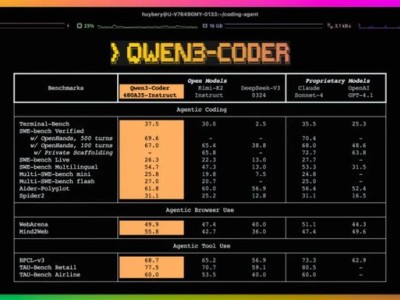
就在刚刚,阿里通义大模型团队开源Qwen3-Coder,直接刷新AI编程SOTA——
不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。

网友当即实测了一把小球弹跳,效果是酱婶的:

效果之强,甚至引来惊呼:简直改变游戏规则。

毕竟,这可是开源的!
现在大家不用再每月花200刀买Claude Code了!

Qwen3-Coder包括多个尺寸,其中最强版本Qwen3-Coder-480B-A35B-Instruct是450B的MoE模型,激活参数为35B
原生支持256K上下文,还可以通过YaRN扩展到1M长度。

命令行版Qwen也同步登场:
通义团队基于Gemini Code,进行了prompt和工具调用协议适配,二次开发并开源命令行工具Qwen Code
嗯,这年头没个CLI都不好意思说自己是编程Agent了(doge)。
简单prompt直出酷炫效果
Qwen3-Coder具体表现如何,还是直接眼见为实。
基本上是,使用简单的语言就能得到惊喜的体验:
比如一句话实现用p5js创建多彩的可交互动画。
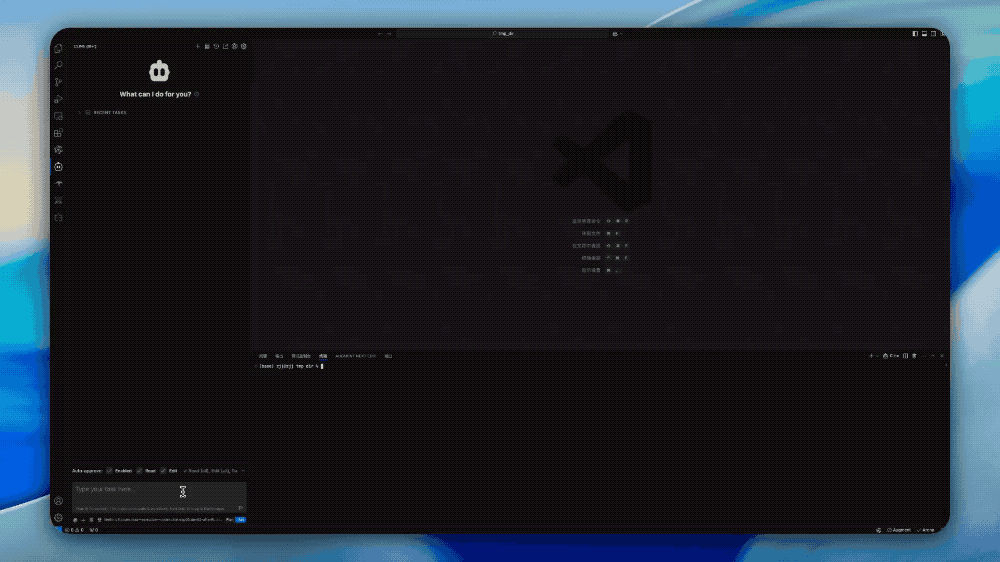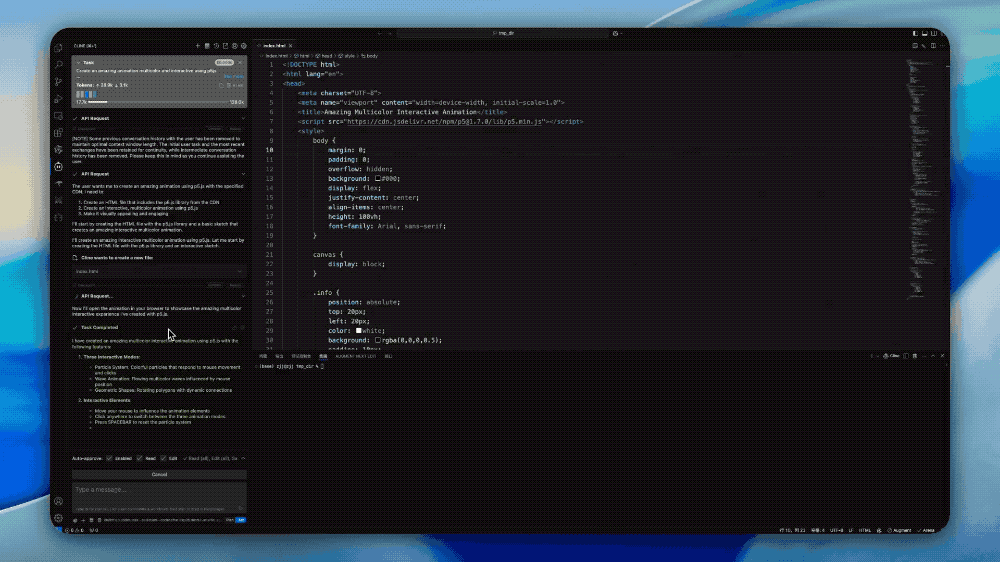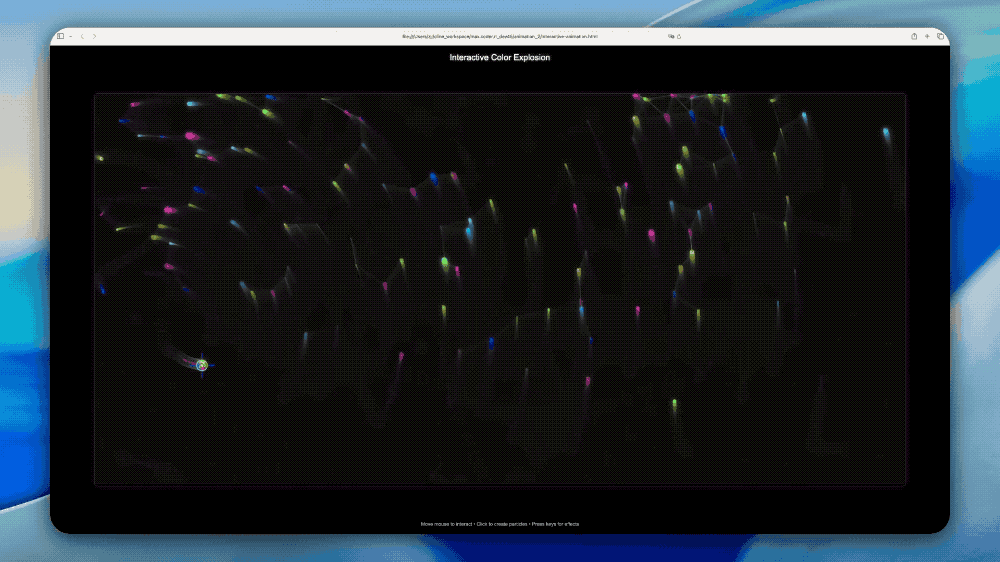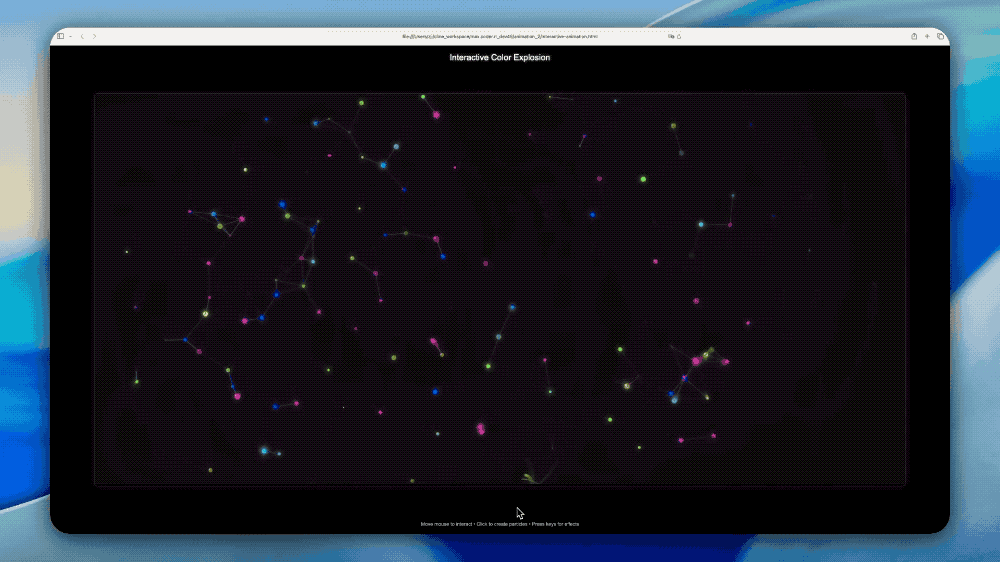
3D地球可视化,分分钟得到一个电子地球仪。
还能做出动态的天气卡片。
可交互的小游戏也能轻松拿捏。
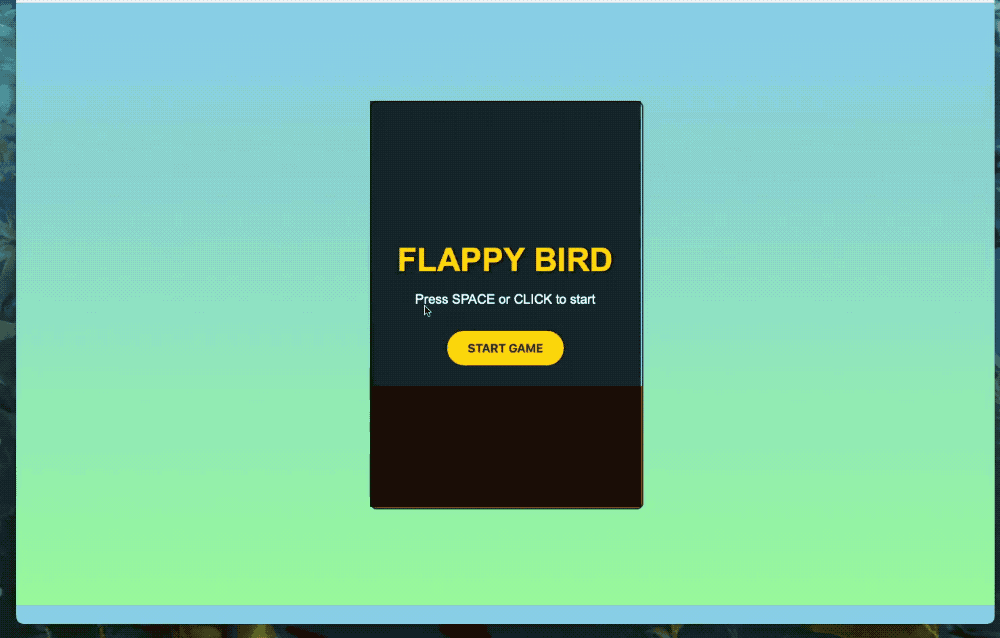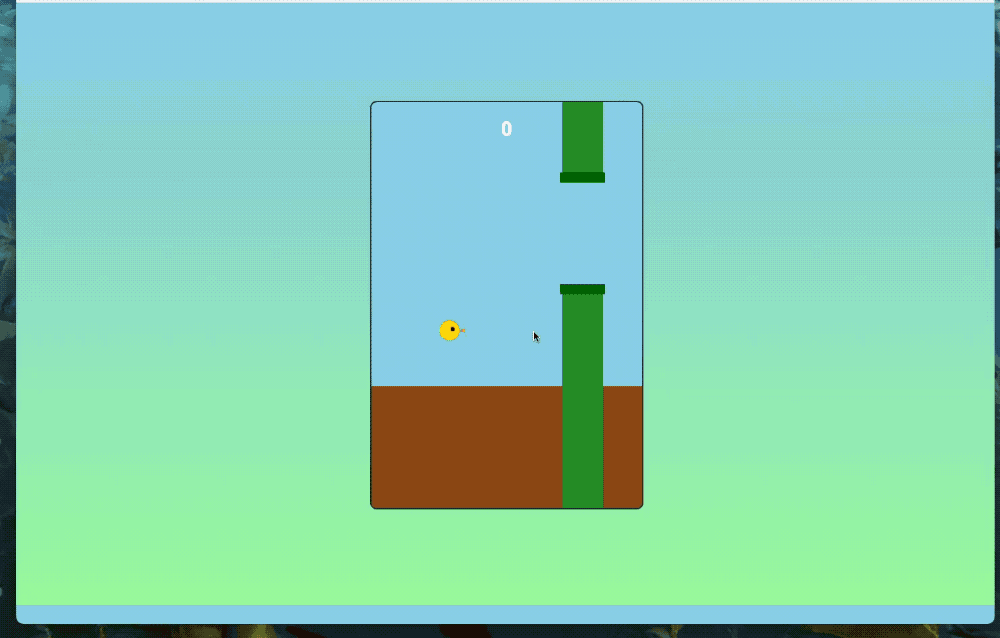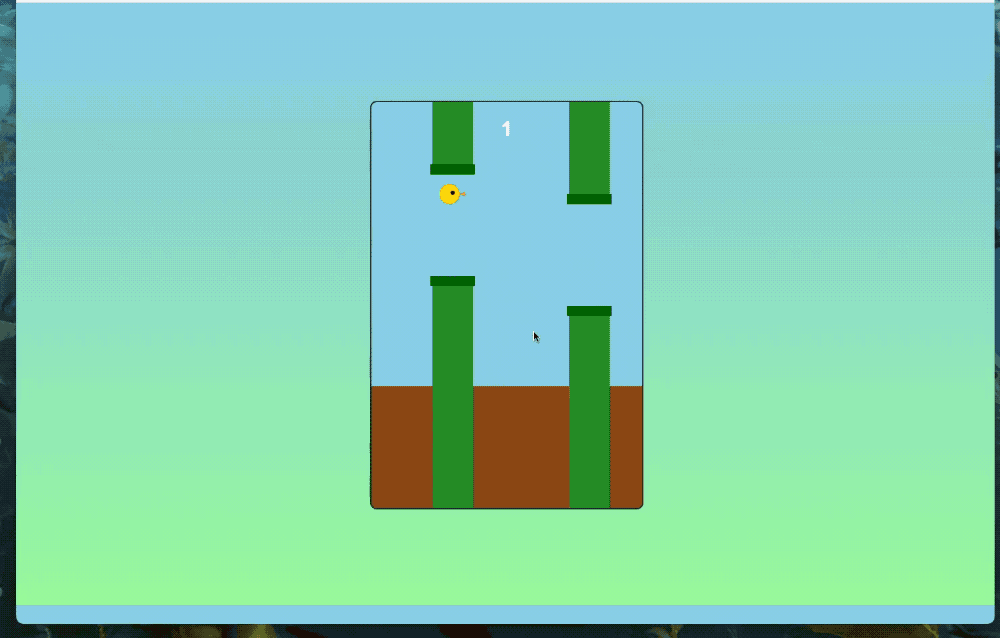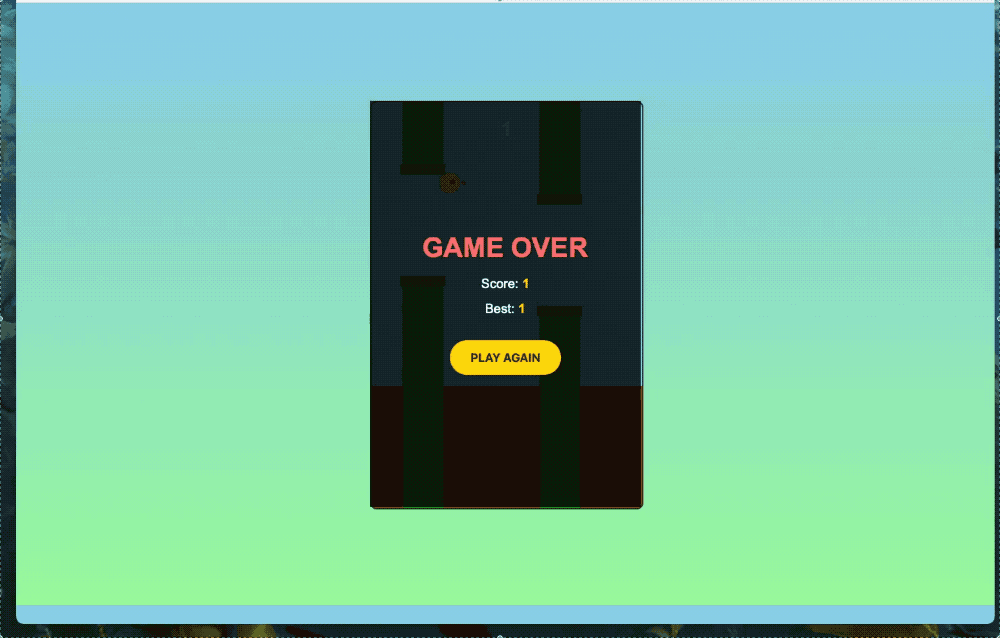
我们也简单实测了一波,先来个最实用的功能——做简历。
提示词是:生成一个可编辑的简历模板。

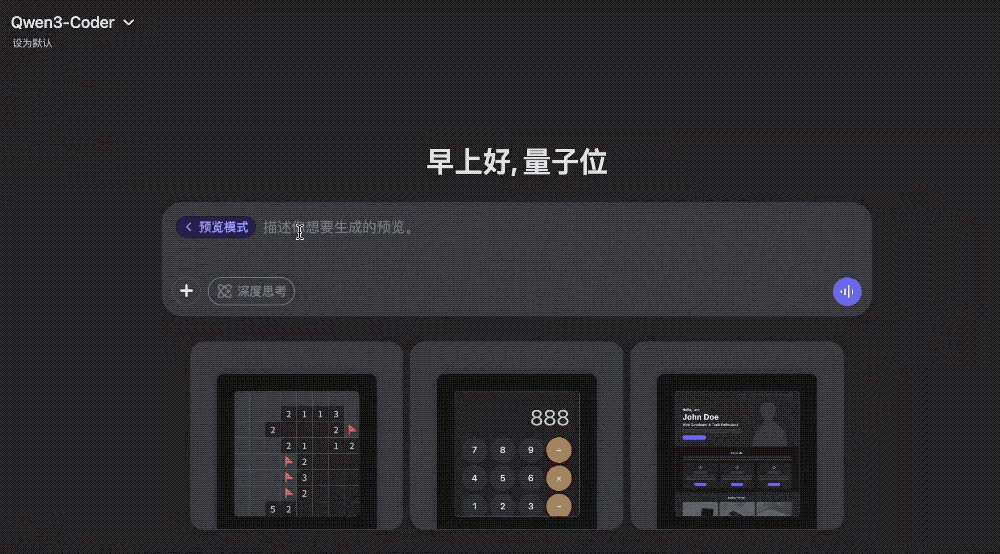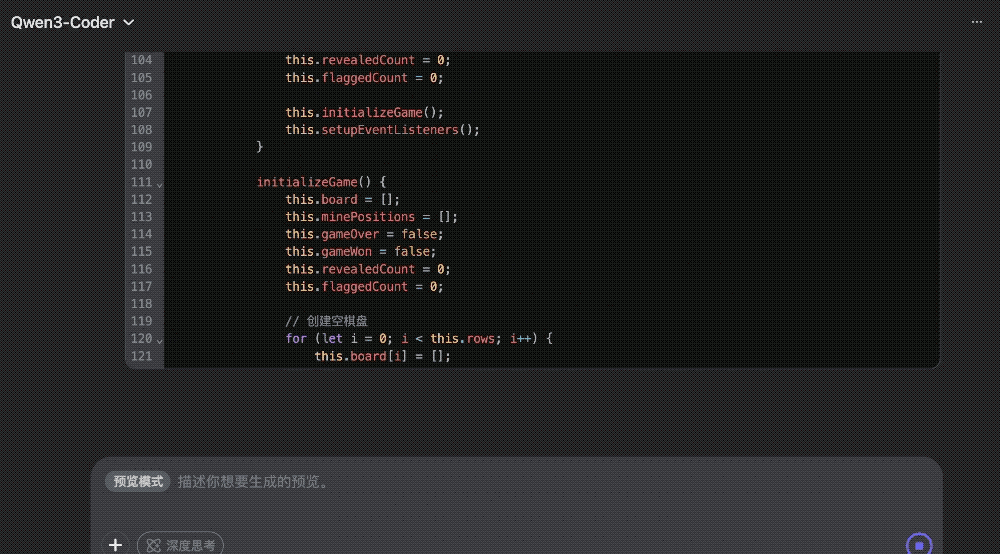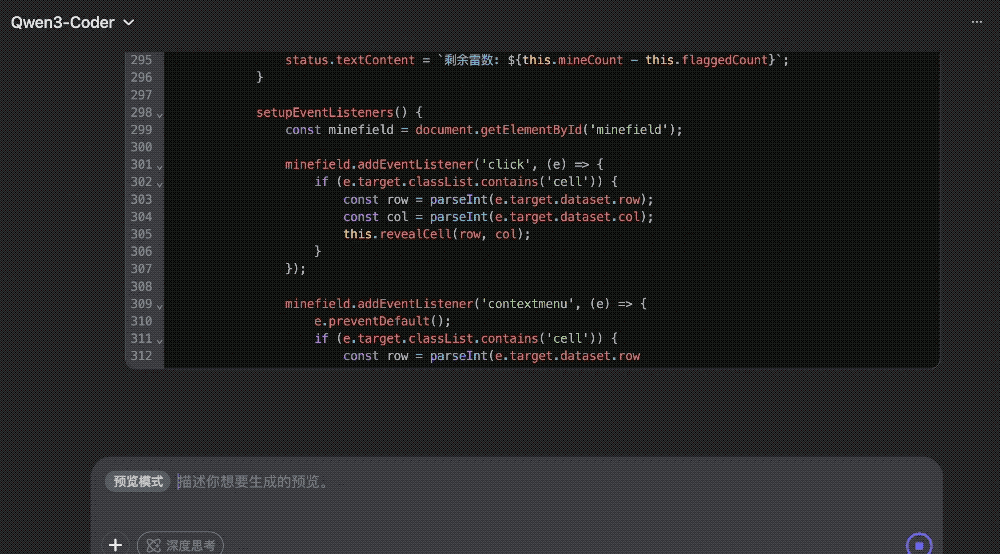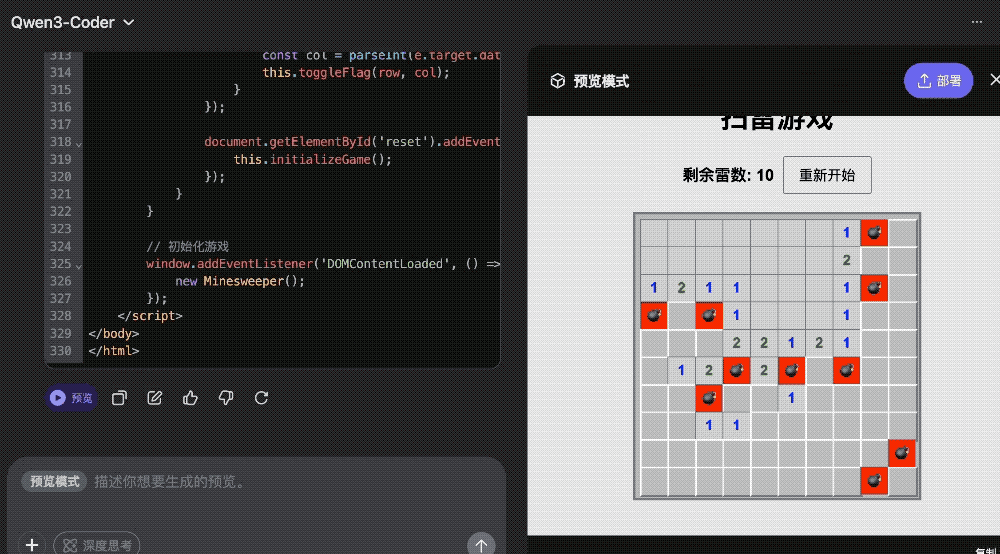
写个扫雷游戏更是轻轻松松,即写即玩~
提示词:生成一个扫雷游戏。
效果之外,值得关注的是,这一次通义团队同样公布了从预训练到后训练的不少技术细节。
技术细节
预训练阶段,Qwen3-Coder主要还是从不同角度进行Scaling,以提升模型能力。
包括数据扩展、上下文扩展、合成数据扩展
其训练数据的规模达到7.5Ttokens,其中70%为代码数据,在保证通用与数学能力的同时提高了编程能力。
同时,原生支持256K上下文长度,借助YaRN技术可以扩展至1M,适配仓库级和动态数据处理。
在训练中还利用Qwen2.5-Coder对低质量数据进行了清洗与重写,显著提升了整体数据的质量。
与当前热衷于竞赛类编程的模型不同,Qwen团队认为代码任务天然适合执行驱动的大规模强化学习。
因此在后训练阶段,他们一方面通过Scaling Code RL在丰富、真实的代码任务上扩展训练,自动生成多样化测试用例,提高了代码执行的成功率。

另一方面,引入了Scaling Long-Horizon RL,依托阿里云基础设施构建可以同时运行20000个独立环境的系统,让模型在多轮交互中表现优异,尤其是在SWE-bench Verified上实现了开源模型SOTA的效果。

开源 vs 闭源
看到这里,你是不是也摩拳擦掌想要一试Qwen3-Coder的真实实力了?
帮大家指个路:
最简单的,可以直接在Qwen官网体验;命令行安装Qwen Code,支持OpenAI SDK调用LLM;在阿里云百炼平台申请API,Claude Code、Cline等编程工具都能搭配起来用。
Qwen3-Coder依然遵循的是Apache License Version 2.0,商用友好。
反正开源嘛,主动权已经交到了各位开发者手里~
而这也是Qwen此番发布,引得网友刷屏转发的关键所在:
Qwen3-Coder看起来是开源编程Agent的一次重大飞越。

现在是比肩,超越还会远吗?

而更令人兴奋的是,在开源这条路上,中国模型们当之无愧地正走在最前列。
官网:https://chat.qwen.ai/项目地址:https://github.com/QwenLM/qwen-codehttps://mp.weixin.qq.com/s/CArpTOknOQC5O90Wgih3SA
— 完 —