在互联网信息爆炸的时代,人们面临着前所未有的信息检索挑战。记忆力的局限、注意力的分散,以及处理多任务时的力不从心,使得从海量数据中迅速找到所需信息变得愈发困难。然而,技术的革新正逐步缓解这一困境。阿里巴巴的通义实验室近期推出的开源AI Agent框架WebSailor,以其卓越的性能,在信息检索领域掀起了一场技术革命。
WebSailor在多个基准测试中展现了其强大的实力。在BrowseComp-en/zh测试中,它不仅超越了所有现有的开源智能体,甚至能与某些专属闭源模型相媲美。这一成绩无疑是对其技术实力的有力证明。
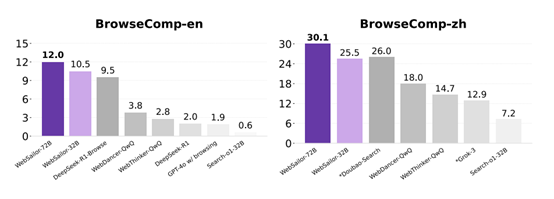
不仅如此,WebSailor在简单任务上的表现同样令人瞩目。在SimpleQA基准测试中,它成功超越了所有其他方法,进一步巩固了其在信息检索领域的领先地位。
WebSailor的成功,得益于其独特的核心技术——复杂任务生成与强化学习模块的紧密配合。为了模拟真实世界的信息环境,研究团队构建了复杂的知识图谱,这些图谱通过随机游走的方式生成,具有高度的非线性和复杂性。在此基础上,团队还采用了子图采样和信息模糊化技术,进一步增加了任务的难度和不确定性。
在强化学习模块方面,WebSailor采用了两阶段的训练方法。首先是基于拒绝采样的微调(RFT)冷启动阶段,通过筛选高质量的轨迹,为模型提供了基本的工具使用能力和推理框架。接着是强化学习(RL)阶段,团队提出了DUPO算法,通过动态采样策略优化训练过程,提高了模型的推理能力和样本效率。
WebSailor还采用了基于规则的奖励机制,确保了模型生成的轨迹既符合要求又准确。这种奖励机制结合了格式验证和答案验证,有效地引导模型在复杂的任务环境中进行优化。
WebSailor的开源,无疑为信息检索领域注入了新的活力。它不仅提供了强大的技术解决方案,还促进了技术的共享和交流。目前,WebSailor在Github上已经获得了超过5000颗星的关注,其每日增长趋势更是一度位居榜首。
随着技术的不断进步和应用场景的不断拓展,WebSailor有望在未来在信息检索领域发挥更加重要的作用。同时,我们也期待更多的开源项目能够涌现出来,共同推动技术的创新和发展。