
小红书在AI领域再次发力,近两个月内连续开源了三款自研模型,其中最新推出的dots.vlm1是首个多模态大模型。这款模型基于小红书人文智能实验室(Humane Intelligence Lab,简称hi lab)自研的视觉编码器构建,不仅在视觉理解和推理任务上表现卓越,还能应对数独解题、高考数学题解答等复杂任务,甚至能模仿李白诗风创作诗句。
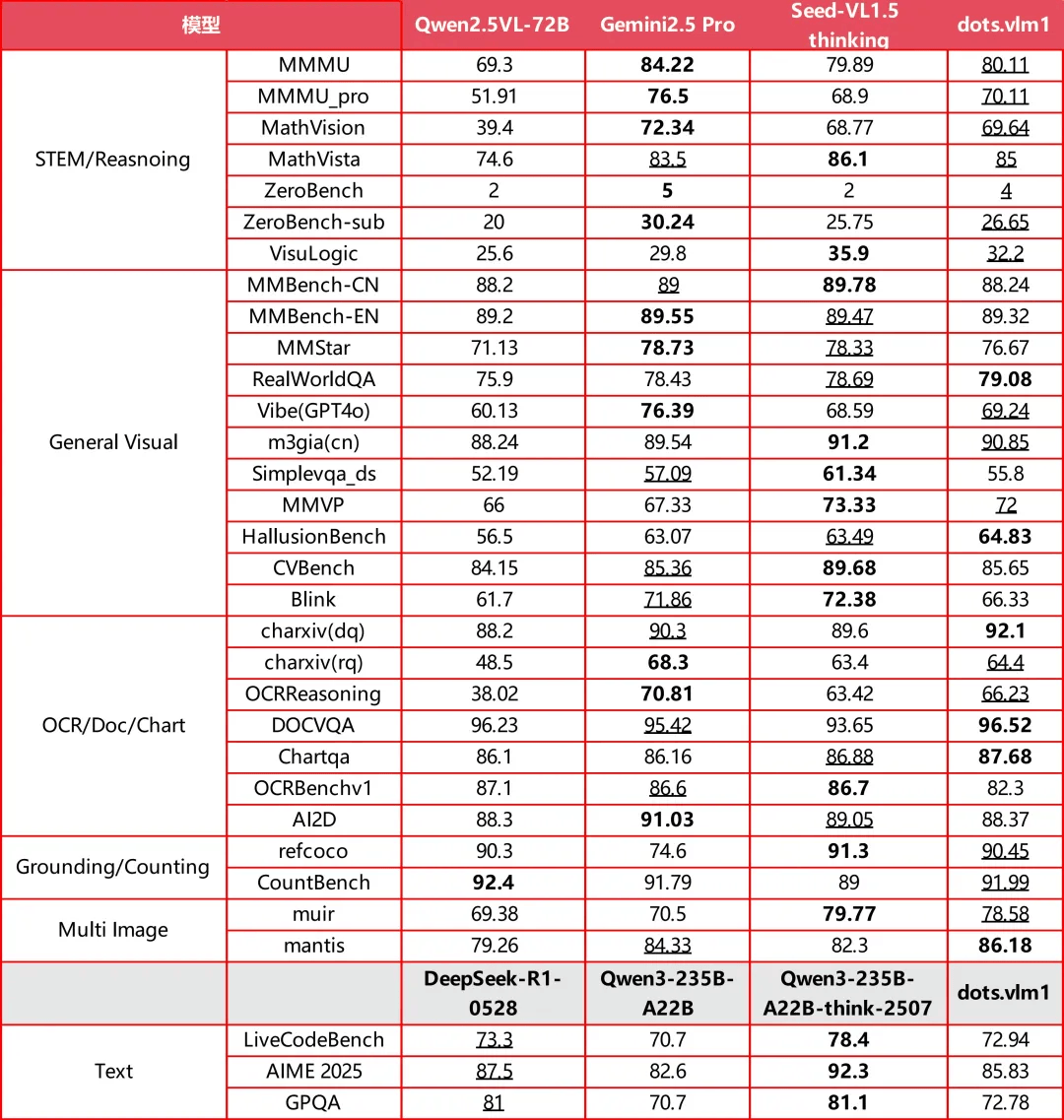
在AI技术日新月异的当下,小红书的这次开源行动无疑为行业带来了新的活力。OpenAI、谷歌等国际巨头也在近期发布了新的开源模型,但相比之下,dots.vlm1的多模态能力显得尤为突出。据官方介绍,dots.vlm1在视觉评测集如MMMU、MathVision、OCR Reasoning上的表现已接近当前领先的Gemini 2.5 Pro与Seed-VL1.5 Thinking模型,显示出强大的图文理解与推理能力。
在文本推理任务上,dots.vlm1的表现也相当出色,能够处理AIME、GPQA、LiveCodeBench等复杂任务。尽管在数学和代码能力上已具备一定的通用性,但在GPQA等更多样化的推理任务上仍有一定提升空间。不过,整体而言,dots.vlm1在视觉多模态能力方面已接近业界最高水平。
小红书hi lab在上周开源的dots.ocr文档解析模型也引起了广泛关注,该模型以17亿参数的“小模型”实现了业界领先的性能,成功登上Huggingface热榜第七。这一系列动作表明,hi lab在AI技术自研方面正不断加大投入,致力于拓展人机交互的可能性。
dots.vlm1的成功不仅在于其卓越的性能,更在于其背后的技术架构和训练策略。该模型由全自研的12亿参数NaViT视觉编码器、轻量级MLP适配器和DeepSeek V3 MoE大语言模型构成,通过三阶段流程进行训练。其中,NaViT视觉编码器从零开始训练,原生支持动态分辨率,为模型的高分辨率输入提供了充足的表示容量。
在预训练阶段,dots.vlm1使用了大量跨模态互译数据和跨模态融合数据,旨在增强模型的多模态能力。这些数据涵盖了普通图像、复杂图表、OCR场景、视频帧等多种类型,为模型提供了丰富的训练素材。通过这些数据的训练,dots.vlm1能够在图文混合上下文中执行下一token预测,避免过度依赖单一模态。
对于小红书而言,自研多模态大模型不仅是技术实力的体现,更是为了更好地理解用户和内容,提升个性化推荐的精准度。随着月活用户超过3.5亿,小红书每天都会产生海量的图文内容。如何更好地处理这些内容,让AI更懂用户,成为小红书面临的重要课题。而dots.vlm1的推出,无疑为这一课题的解决提供了有力支持。
小红书hi lab还在不断壮大dots模型家族,未来或将推出更多基于dots的多模态模型。这些模型有望与小红书的应用产品紧密结合,进一步提升用户体验。同时,小红书也在积极招募“AI人文训练师”团队,帮助AI更好地进行后训练,以应对更加复杂和多样化的任务。
随着AI技术的不断发展,多模态能力已成为通向AGI(通用人工智能)的必经之路。小红书通过自研多模态大模型,不仅提升了自身的技术实力,也为行业树立了新的标杆。未来,我们期待看到更多像dots.vlm1这样的优秀模型涌现,共同推动AI技术的进步和发展。











