
OpenAI近日震撼发布其最新旗舰人工智能模型GPT-5,该模型将作为技术支持,驱动公司下一代ChatGPT产品的革新与发展。GPT-5的问世,标志着OpenAI在人工智能领域迈出了重要一步,它不仅融合了O系列模型的卓越推理能力,还继承了GPT系列响应迅速的特点,成为OpenAI首个“统一”的人工智能模型。
周四,随着GPT-5的发布,ChatGPT及其背后的OpenAI正式步入了一个全新的时代。GPT-5的推出,不仅彰显了OpenAI开发更接近智能代理而非传统聊天机器人系统的雄心壮志,更预示着人工智能技术的又一次飞跃。相较于GPT-4,GPT-5不仅能让ChatGPT对各种问题作出智能回应,更能代表用户执行多种任务,如创建软件应用、管理日程或生成研究报告。
GPT-5的加入,让ChatGPT的使用体验更加流畅。该模型内置实时路由机制,能够自主决定最佳答案的提供方式,无需用户手动选择设置。无论是快速回应还是深度思考,GPT-5都能游刃有余。
在发布会上,OpenAI首席执行官山姆·奥特曼盛赞GPT-5为“世界上最出色的模型”,并指出这是公司在开发能够超越人类执行高经济价值工作的人工智能(即人工通用智能AGI)道路上的一次重大突破。奥特曼表示:“GPT-5这样的技术,在历史上任何时期都是难以想象的。”
从周四起,GPT-5将作为默认模型,对所有ChatGPT免费用户开放。这是OpenAI首次让免费用户接触到人工智能推理模型,此前这类更先进的模型仅对付费用户开放。负责ChatGPT的OpenAI副总裁尼克·特利表示,这一决定是OpenAI践行其使命——让尽可能多的人接触到先进人工智能技术——的重要一步。
自2022年ChatGPT让OpenAI声名大噪以来,GPT-5无疑是该公司最受期待的产品发布之一。如今,ChatGPT已成为全球最受欢迎的消费级产品之一,每周用户超过7亿,约占全球人口的10%。GPT-5的发布,不仅吸引了业界的广泛关注,更被视为人工智能整体发展的风向标。
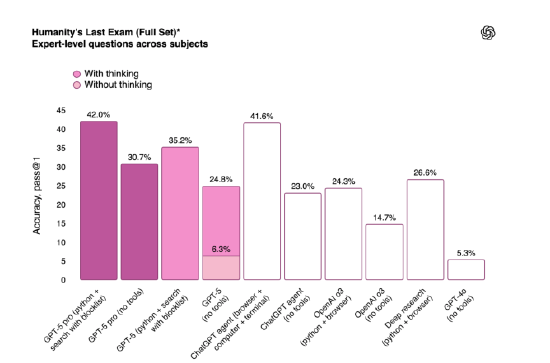
在多个领域,GPT-5均展现出了领先水平。在基于GitHub真实编程任务的SWE-bench Verified测试中,GPT-5首次尝试的得分高达74.9%,略优于Anthropic的Claude Opus 4.1和谷歌DeepMind的Gemini 2.5 Pro。在衡量人工智能模型在数学、人文和自然科学领域表现的“人类终极考试”中,GPT-5 Pro在使用工具的情况下得分42%,虽略低于xAI的Grok 4 Heavy,但仍表现出色。在针对博士级科学问题的GPQA Diamond测试中,GPT-5 Pro首次尝试得分89.4%,同样超过了竞争对手。
在健康领域,GPT-5的表现同样令人瞩目。在衡量人工智能模型健康领域回应准确性的测试“HealthBench Hard Hallucinations”中,GPT-5(启用思考功能时)的幻觉率仅为1.6%,远低于GPT-4o和o3模型。尽管人工智能聊天机器人并非医疗专业人员,但GPT-5能更主动地提示潜在健康问题,帮助用户解读医疗检查结果,从而为用户提供更可靠的健康建议。
GPT-5在创意设计、写作等主观领域也优于其他人工智能模型。特利表示,GPT-5在创意任务中的回应更加自然,展现出“更好的品味”。同时,GPT-5的准确性也得到了显著提升,与O系列模型相比,其幻觉现象大幅减少。在Tau-bench测试中,GPT-5的表现虽有好坏参半,但整体而言仍保持了较高水准。
GPT-5的发布,不仅带来了技术上的革新,还为ChatGPT带来了多项用户体验升级。用户现在可以在设置中选择四种新的人格类型,这些人格将自动调整ChatGPT的回应方式。同时,ChatGPT Plus和Pro订阅用户将享有更高的GPT-5使用限额和访问权限。
对于开发者而言,GPT-5将以三种规格通过OpenAI的API开放。开发者现在可以通过API控制回应的详细程度,并根据任务需求选择不同规格的模型。GPT-5基础模型对开发者的收费也相对合理,为每百万输入令牌1.25美元,每百万输出令牌10美元。
在GPT-5发布之前,OpenAI还发布了开源权重推理模型gpt-oss,供开发者和企业免费下载使用。尽管GPT-5在编程等领域树立了新的前沿性能标准,但在多个领域,它似乎与其他前沿人工智能模型相当。然而,基准测试只是反映模型表现的一部分,GPT-5在现实世界中的应用效果以及是否真正超越竞争对手,仍有待观察。











