在大数据领域,企业如何构建高效、稳定且安全的数据仓库一直是技术探讨的热点。近期,阿里云大数据的技术专家祎休在一场直播课程中,深入分享了基于阿里云数加MaxCompute构建企业级大数据仓库的实践经验和思路。
面对这些挑战,阿里云在构建数据仓库的过程中,提出了稳定、可信、丰富、透明的四大衡量标准。一个完备的大数据仓库应具备海量数据存储与处理能力、多样的编程接口和计算框架、丰富的数据采集通道以及严格的安全防护措施。在架构设计上,阿里云采用了自上而下与自下而上相结合的方法,注重高容错性,确保系统稳定,并将数据质量监控贯穿于整个数据处理流程。
在模型设计上,业界通常采用维度建模和实体建模两种方法。维度建模结构简单,便于事实数据分析,适合业务分析报表和BI;而实体建模结构复杂,便于主题数据打通,适合复杂数据内容的深度挖掘。阿里云在实际应用中,星型模型和雪花模型并存,以优化数据应用和减少计算资源消耗。
数据处理分层方面,阿里云采用了上下三层结构,包括基础数据层、数据中间层和数据集市层。这样的设计旨在压缩数据处理流程,提高数据质量控制和数据运维效率。其中,流式处理作为数据体系的一部分,使得数据更具时效性,价值更高。
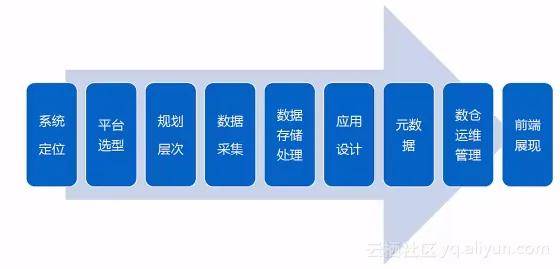
阿里云数加平台在构建大数据仓库时,主要分为数据整合、数据体系和数据应用三个层次。结构化数据采集涉及全量采集和增量采集,而在数据量巨大或需要准实时数据的情况下,还会采用实时采集方法。数据仓库与阿里云数加产品的对应关系清晰,为用户提供了便捷的数据处理和分析工具。
数仓的安全性是至关重要的话题。阿里云基于MaxCompute的多租户数据授权模型,提供了高度安全的数据共享机制,有效防治了数据流和访问限制等方面的问题。阿里云还分享了一些架构设计中的最佳实践,如数据表命名规范、分区表和工作流设计,以及计算框架的应用和优化关键路径。
在数据治理方面,阿里云注重保障机制、管理和内容建设,贯穿数据开发的整个过程。为了有效衡量数据治理的效果,阿里云使用了数据管理健康评估体系,能够正确认识数据管理的健康性,并给出数据管理健康分。重复数据治理是数据治理过程中的重要一环,阿里云通过多种手段识别和处理重复数据,确保数据的质量和准确性。
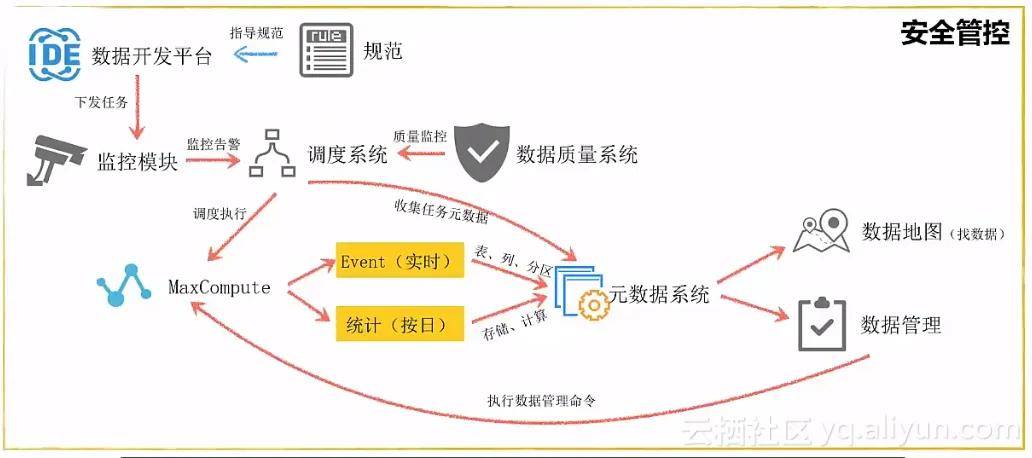
阿里云还建立了完善的数据质量管理体系和数据生命周期管理体系,确保数据的持续质量和有效利用。通过这些措施,阿里云在大数据实践之路上取得了显著成果,为企业级大数据仓库的构建提供了有力支持。