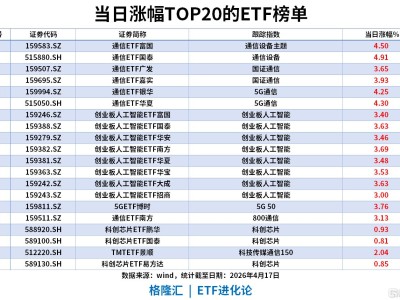
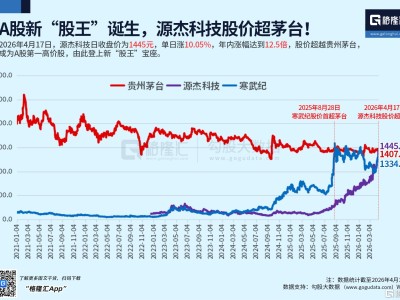
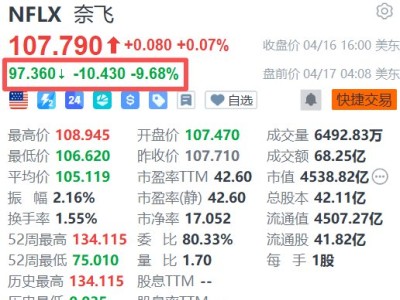
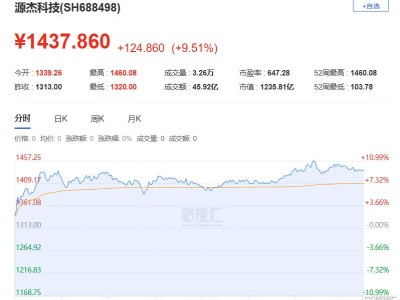
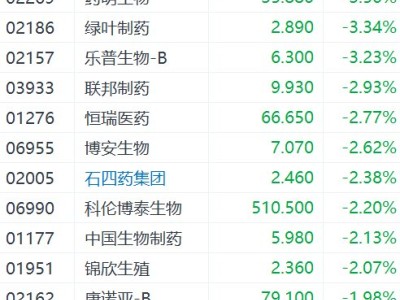
在机器人领域,一场关于技术路径与发展方向的热烈讨论正如火如荼地进行。去年的世界机器人大会(WRC)上,各家公司还在比拼谁家的机器人能更快地行走,而今年的大会则呈现出截然不同的景象。连续三天的展览中,硬件本体展现出多样化的形态,旨在适应不同场景的需求,吸引落地和量产的机会;软件算法方面,VLA、端到端模型、仿真数据训练等技术路线百花齐放。
由于缺乏统一的标准,各家公司的尝试显得天马行空,甚至彼此间存在不兼容的情况,核心路线上也各走各道。然而,这正是新兴行业初期的常态。非共识是推动技术探索、寻找真理的关键动力。在经历了初期的模仿和复现后,行业必然会经历一个剧烈的发散期,随后缓慢收敛,再发散,再收敛,如此循环往复。真正的答案,正是在这一系列的发散与碰撞中被逐渐揭示。
在与多家关键公司的交流中,我们梳理出了几个充满争议的领域。这些正在激烈碰撞的“非共识”,或许将成为影响机器人领域未来的关键问题。
首先,关于算法与数据的争议尤为突出。宇树科技创始人王兴兴认为,当前机器人行业对数据关注过多,而对模型关注不足。他指出,即便拥有大量高质量数据,由于模型架构不够优秀和统一,训练出的模型仍难以真正落地。与之相对,星海图联合创始人许华哲则强调数据的重要性,他认为数据决定了能力的下限和基础,是完成关键跨越的核心。

接下来,关于仿真数据能否替代真实数据的问题也备受关注。由于真实物理世界的数据稀缺、自采成本高,部分模型厂商选择使用视频数据或仿真数据进行训练。银河通用创始人王鹤认为,在具身智能发展的初期阶段,合成数据是推动产业发展的关键数据资产。然而,自变量创始人兼CEO王潜则持不同观点,他认为手部复杂操作无法通过仿真数据来进化,尽管导航、走路等任务更适合用仿真数据训练。
关于数据飞轮的起点——需要多少数据、如何获取高质量数据的问题也普遍存在争议。维他动力方面认为,决定智能涌现的关键是数据的多样性而非数量,因此应让机器人在物理世界中探索以获取足够多样的场景数据。星海图则坚持高质量的一万小时数据是数据飞轮的起点,但目前整个行业极度缺乏数据。
在构建机器人“大脑”的问题上,技术分歧尤为显著。宇树科技对VLA模型持怀疑态度,认为世界模型的收敛方向更快;星海图则采用分层系统,认为分层是通往完全端到端的必经之路;自变量则坚持做完整端到端的统一大模型;而越疆机器人则强调操作系统的重要性,认为构建一个具身智能的未来操作系统更为关键。

最后,关于软件与硬件的关系也引发了广泛讨论。星海图认为硬件资源应根据AI模型的能力进行优化投入;越疆机器人和加速进化则认为机器人可能会重演手机的发展路径,先由硬件厂商带动产业热度,再由“大脑”和“应用”主导行业分层;众擎机器人则强调软件与硬件共同决定机器人的价值;源络科技则主张机器人应通过与物理世界交互主动学习,而非依赖语言模型的堆砌。
在开源问题上,行业内也存在不同看法。星海图认为真正的开源应包含经过验证的数据和模型权重,让其他人能在此基础上进行微调和二次开发;而自变量则指出,由于具身模型依赖于硬件,即使模型开源,硬件系统闭源也难以让其他公司利用上这些模型。