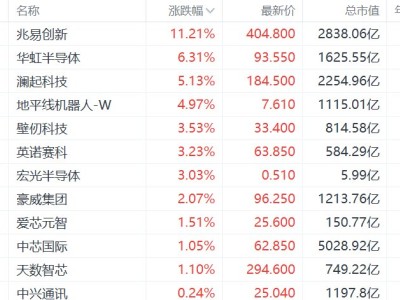
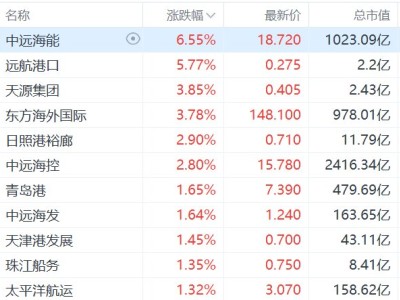
近期,有关GPT-5编程能力的讨论在科技圈内引发了广泛关注。有细心网友发现,OpenAI在评估GPT-5编程能力时,似乎并未完全遵循自己提出的SWE-bench Verified标准。
据悉,SWE-bench是业界公认的评估模型自主编程能力的基准之一,而SWE-bench Verified则是其经过精心筛选的子集,原本包含500个问题。然而,OpenAI在测试GPT-5时,却仅使用了其中的477个问题。
这一发现立即引发了质疑。为何OpenAI要省略掉这23个问题?有网友指出,早在GPT-4.1发布时,OpenAI就曾以部分问题无法在其基础设施上运行为由,忽略了部分测试题。如今,这一操作在GPT-5上再次上演,难免让人对其测试结果的公正性和准确性产生怀疑。
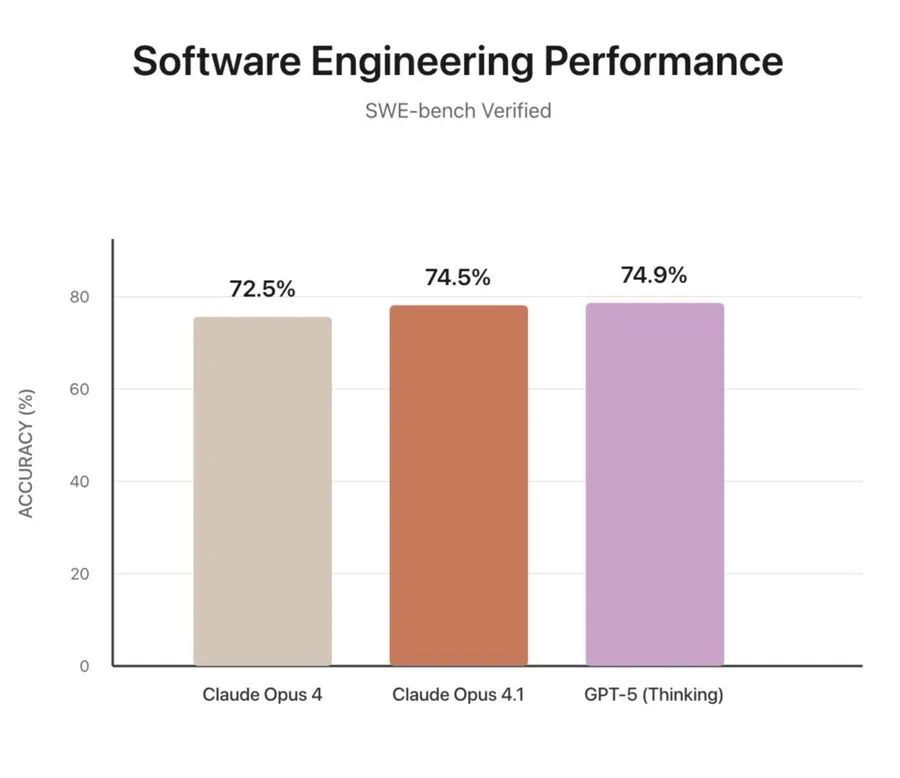
更令人惊讶的是,有网友发现,如果这23个被省略的问题默认得零分,那么GPT-5的得分实际上与Claude Opus 4.1相比并无显著优势。这一发现无疑给GPT-5的编程能力蒙上了一层阴影。
值得注意的是,OpenAI在提出SWE-bench Verified时,曾明确表示这是为了更准确地评估模型的编程能力。他们与SWE-bench的作者合作,共同发起了一项人工注释活动,筛选出了500个经过验证的样本。然而,如今他们却自行缩减了这个子集,这无疑是对自己提出标准的背叛。
网友们还发现,OpenAI在比较GPT-5与Claude Opus 4.1时,存在不公平之处。他们是将经过最大思维努力的GPT-5与未扩展思维的Opus 4.1进行比较,这种比较方式显然没有参考价值。
面对这些质疑和发现,OpenAI尚未给出正式回应。然而,这一事件已经引发了业界对大型语言模型评估标准的深入讨论。有专家指出,为了确保评估结果的公正性和准确性,应该制定更加严格和统一的评估标准,并避免自行更改或缩减测试集。
与此同时,也有网友表示,虽然GPT-5的编程能力可能并不如OpenAI所宣传的那么强大,但它仍然是一款非常优秀的语言模型。他们期待OpenAI能够正视这些问题,并不断改进和完善自己的模型。
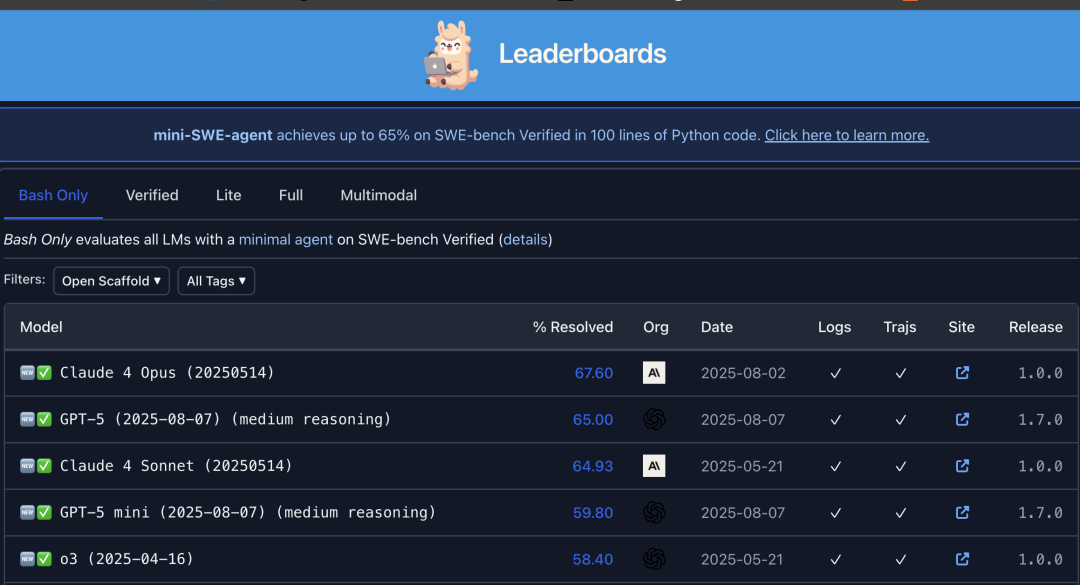
在SWE-bench这一最原始的榜单中,Claude 4 Opus仍然占据着领先位置。这也从一个侧面反映了当前大型语言模型评估的复杂性和多样性。对于用户来说,选择哪款模型取决于他们的具体需求和场景。而对于模型开发者来说,不断提升模型的性能和准确性才是永恒的追求。