在学术研究的浩瀚宇宙中,人工智能助手正逐渐成为不可或缺的力量。然而,一个紧迫的问题也随之浮现:当我们依赖AI撰写研究报告时,如何确保其质量?这好比我们聘请了一位新助手,自然需要一套方法来衡量其工作成效。
字节跳动BandAI团队的一组研究人员,包括李明昊、曾颖、程志豪、马聪和贾凯,在2025年8月于arXiv预印本平台发表了一项开创性研究,论文编号为arXiv:2508.15804v1。他们提出了一种全新的解决方案,详情可见于https://github.com/ByteDance-BandAI/ReportBench,这里提供了完整的研究代码和数据。
市面上现有的AI研究助手,例如OpenAI的Deep Research和谷歌的Gemini Deep Research,虽能迅速完成原本耗时冗长的文献调研工作,但评估这些AI生成报告的质量却成为一大难题。这好比一个飞速运转的工厂,却缺乏相应的质量检测机制。
为了填补这一空白,研究团队打造了一个名为“ReportBench”的评估系统。该系统摒弃了人工专家主观判断的依赖,转而利用经过同行评议的高质量学术综述论文作为评估基准。这些论文代表了该领域的权威观点,如同标准化的考试题目。
评估流程包含两大核心环节。首先,它检查AI助手引用的参考文献质量,通过对比AI生成报告中的引用与综述论文中的引用,评估其重合度。其次,它验证报告中每个陈述的准确性,对于有引用的陈述核实原始文献,对于无引用的陈述则通过网络搜索验证。
在具体操作中,研究团队设计了一种“逆向工程”方法。他们从arXiv数据库中筛选出678篇高质量综述论文,让AI系统分析这些论文的标题、摘要和发表时间,自动生成研究提示词。为了增加多样性,他们还设计了不同详细程度的提示词。
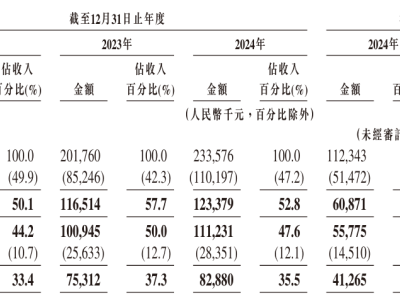
评估结果显示,OpenAI的Deep Research在引用准确性方面表现优异,平均每份报告引用约10篇文献,其中38.5%与专家选择的文献重合。而Gemini Deep Research虽然引用数量更多,但准确性相对较低。一些基础AI模型在配备搜索工具后也展现出潜力。
研究还发现,许多AI系统存在“陈述幻觉”和“引用幻觉”问题。例如,OpenAI Deep Research在分析某篇强化学习论文时,错误地将某位学者的贡献归因到另一篇论文。这些问题虽看似细微,但在学术研究中可能产生误导。

为了构建更全面的评估体系,研究团队还开发了一套自动化的事实核查流程。对于有引用的陈述,系统会自动抓取原始网页内容并判断陈述是否得到原文支持;对于无引用的陈述,系统则采用多个联网AI模型投票机制验证其准确性。
从应用角度来看,这项研究为AI研究助手的改进提供了方向。当前的AI系统在生成报告时往往“过度引用”,未来的改进应聚焦于提高引用的精准度。加强对特定领域知识的训练,减少事实性错误,也是亟待解决的问题。
ReportBench为我们带来了首个系统性评估AI研究助手的标准化工具,为快速发展的AI助手行业建立了“质量检测标准”。尽管当前的AI系统仍存在不足,但有了这一评估基准,我们能够更好地追踪进步、发现问题并推动改进。
对于普通用户而言,这项研究提醒我们在使用AI研究助手时需保持警惕。虽然这些工具能提高工作效率,但我们仍需对其输出进行核实和验证。在追求效率的同时,准确性和可靠性始终是学术研究的基石。
Q&A
Q1:ReportBench评估系统是什么?它是如何运作的?
A:ReportBench是字节跳动团队开发的AI研究助手评估系统。它利用已发表的高质量学术综述论文作为基准,通过对比AI生成报告的引用质量和陈述准确性来评估AI助手的表现。
Q2:OpenAI和谷歌的AI研究助手表现如何?
A:OpenAI Deep Research在引用准确性上表现更佳,其38.5%的引用与专家选择重合。而Gemini Deep Research虽然引用数量更多,但准确性相对较低。两者都存在陈述和引用问题,用户需谨慎使用。
Q3:普通人使用AI研究助手时应注意什么?
A:应保持警惕并进行必要核实。AI助手可能出现“过度引用”和编造不存在的论文链接等问题。使用时,应重点检查关键引用的真实性,并对无引用支持的重要陈述进行独立验证。