随着人工智能大模型参数规模从千亿迈向万亿级,智算集群对存储系统的需求正经历颠覆性变革。以GPT-4为例,其1.8万亿参数的模型训练需在2万张A100 GPU上持续运行90天,期间产生的数据吞吐量高达PB级,仅单个checkpoint文件就达4TB。这种超大规模计算场景下,传统存储方案在协议兼容性、吞吐性能、数据管理效率等维度暴露出严重短板,成为制约AI训练效率的关键瓶颈。
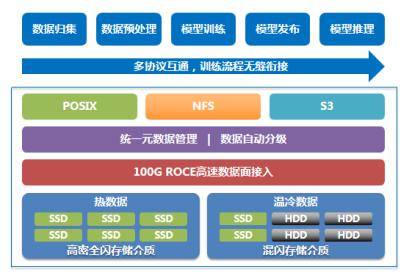
在数据全生命周期管理中,不同训练阶段对存储协议的需求呈现显著差异。数据归集阶段需处理跨地域、跨网络的PB级非结构化数据,涵盖文本、图像、视频等多元格式,对象存储因其跨域传输优势成为首选;预处理阶段则要求对数据进行清洗、脱敏和格式转换,S3协议与NFS协议需并行工作;模型训练阶段对存储系统提出更高要求,既要支持训练数据的高速读写,又要实现checkpoint的秒级保存与恢复,文件存储成为核心载体;模型发布阶段则需通过对象存储实现广域网部署。传统方案采用对象、文件、块存储独立集群的模式,导致数据在不同系统间反复迁移,PB级数据拷贝耗时长达数天,GPU因等待数据传输产生的空闲时间超过15%,直接拉低整体训练效率。
存储系统面临的性能挑战呈现指数级增长。当1750亿参数的GPT-3模型进行checkpoint保存时,数万张GPU会同时发起4TB级数据写入,引发"写风暴"。这种突发性I/O洪峰对存储集群的聚合带宽提出严苛要求,而传统方案受限于故障域约束,集群节点数难以突破,导致存储稳定性与性能需求形成尖锐矛盾。更严峻的是,数据冷热状态随训练进程动态变化,热数据需驻留在高成本SSD介质,冷数据则应迁移至HDD存储。但传统方案缺乏自动分级能力,导致高性能存储长期被低频数据占用,资源利用率不足40%,同时需额外投入算力进行人工数据搬迁。
针对上述痛点,中国移动创新提出多协议融合存储架构,通过四大核心技术实现存储系统质变。在介质层构建双池架构:热数据池采用全闪介质,温冷数据池采用混闪配置,缓存层部署SSD+HDD混合存储;网络层部署双100Gb RoCE高速互联,构建AI集群与存储集群间的低时延数据通道;协议层基于统一元数据管理,实现POSIX、NFS、S3协议的无缝互通,训练数据无需跨池拷贝;管理层开发智能分级引擎,根据数据访问频次自动在全闪池与混闪池间迁移数据。该架构在哈尔滨1.8万卡智算中心的实践表明,48PB集群可提供6.4TB/s读带宽和3.5TB/s写带宽,单个checkpoint保存时间压缩至秒级,较传统方案提升3倍性能。
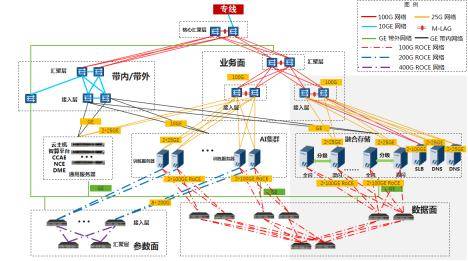
商业化部署成效显著,哈尔滨节点建设的150PB融合存储系统包含60PB全闪存储和90PB混闪存储,支撑九天千亿参数大模型训练效率提升20%。多协议融合技术消除数据冗余存储,使混闪存储容量需求降低40%;高聚合带宽设计避免GPU等待数据传输,算力利用率提高5%;智能分级机制实现数据自动流动,减少20%的全闪空间占用。该创新方案荣获2024年"华彩杯"算力大赛全国总决赛一等奖,相关技术标准已在中国通信标准化协会立项,推动行业存储架构向统一元数据、多协议互通、智能管理方向演进。
中国工程院院士指出,存力、算力、运力的均衡发展是发挥计算效能的关键。在智算集群规模突破万卡级的新阶段,存储系统正从被动支撑转向主动赋能,通过架构创新实现数据流动效率与计算资源利用率的双重提升。这种变革不仅优化了AI训练的经济性,更为超大规模模型研发提供了可靠的存储基础设施保障。