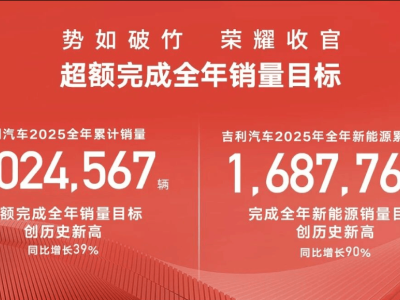
上海AI独角兽企业MiniMax稀宇极智近日掀起技术发布热潮,在短短一周内连续推出四款全模态大模型,涵盖文本、视频、语音和音乐生成领域。这一系列突破性成果不仅展现了中国AI企业在基础研究领域的硬实力,更以颠覆性技术路径和商业模式重塑全球AI产业格局。
文本大模型M2的开源发布成为全球开源社区的里程碑事件。这款仅含100亿激活参数的轻量级模型,在权威测评榜单Artificial Analysis中以总分全球第五、开源模型第一的成绩杀入第一梯队。其综合成本低至0.53美元/百万Tokens,仅为国际同类产品Claude 4.5 Sonnet的8%,推理速度却提升近一倍。该模型针对编码与智能体任务深度优化,在自动化支持、研发协作等企业场景中展现出显著优势。更值得关注的是,meta在强化学习实验中直接采用MiniMax首创的CISPO损失函数和FP32 Head技术,标志着中国AI核心算法首次被国际巨头规模化验证。
视频生成领域迎来新标杆海螺2.3模型。该版本在动态捕捉、风格化创作和人物表现三大维度实现质的飞跃:能够精准还原复杂人体动作序列,支持从水墨到游戏CG的多元艺术风格,面部微表情处理达到电影级细腻度。在保持前代定价水平的同时,新模型通过架构优化将效果成本纪录推至新高度,其Fast版本更将批量创作成本降低50%,生成速度提升3倍。
语音交互领域,Speech 2.6模型重新定义行业基准。针对Voice Agent场景优化的首包响应时间压缩至250毫秒,达到全球顶尖水平。新增的Fluent Lora功能可智能修复不流畅录音,生成自然流畅的语音输出,这项突破在有声书制作、个性化语音助手等场景具有广泛应用价值。模型支持专业音频格式无障碍识别,构建起完整的语音交互生态链。
音乐生成模型Music 2.0实现艺术与技术的深度融合。该模型不仅能精准捕捉人声情感层次,支持男女对唱、阿卡贝拉等复杂形式,更可通过参数控制实现"一声千变"的音色变换。在器乐生成方面,模型可创作包含完整歌曲结构的5分钟作品,生成的旋律兼具记忆点与艺术性,编曲层次丰富且律动自然。这项突破使得音乐创作门槛大幅降低,为数字内容产业开辟新可能。
这波技术浪潮背后,折射出中国AI产业的战略转型。从应用层创新到基础算法突破,从技术追赶到标准制定,中国AI企业正构建起自主可控的技术体系。MiniMax的全模态矩阵不仅提供性能卓越的工具链,更通过开源策略推动全球技术普惠。其负责人表示:"我们致力于打破创作形式的边界,让AI成为跨越行业的生产力引擎,每个灵感都能转化为真实价值。"
随着四大模型的商业化落地,数字内容产业迎来变革契机。视频创作者可获得电影级生成工具,开发者能使用更高效的智能体框架,音乐人得以探索无限创作空间。这场由中国AI引领的技术革命,正在重新定义人类与数字世界的交互方式。