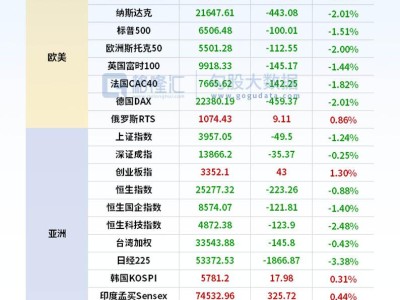
谷歌近日正式推出新一代人工智能模型Gemini 3,在推理能力、交互界面生成及视觉智能领域实现重大突破。该模型由DeepMind团队主导开发,其核心负责人表示,此次升级标志着AI从单纯问答向动态软件生成迈出关键一步。
在复杂任务处理方面,Gemini 3展现出显著提升的逻辑连贯性。团队负责人透露,前代模型在执行5至6步推理时易出现思路中断,而新版本可稳定维持10至15步连贯推理,尤其在税务规划、跨国行程安排及大型代码系统调试等场景中表现突出。在跨学科博士级难题测试中,其得分较前代提升近17个百分点,达到37.5%,远超同类竞品26.5%的准确率。
交互界面生成能力成为本次升级最大亮点。当用户查询历史人物生平或财务计算需求时,模型不再仅提供文字答案,而是直接生成包含图片、时间线及交互元素的完整页面。例如输入"设计投资组合追踪仪表盘"指令后,系统可实时生成可操作的动态界面。这种能力源于模型对按钮、菜单等UI元素的深度理解,在屏幕理解专项测试中取得72.7%的高分,性能达到主要竞争对手的20倍。
代码生成领域同样取得突破性进展。新模型不仅支持自然语言转前端代码,更能根据上下文动态调整界面布局。配合谷歌同步推出的代理开发平台,开发者通过自然语言描述即可获得功能完整且设计美观的代码模块。在Web开发能力评测中,该模型以1487 Elo的评分位居榜首。
实际应用场景中,Gemini 3已展现出超越传统助手的潜力。早期演示显示,模型可深度接入用户邮箱系统,自动分类邮件、拟定回复甚至清空收件箱。这种从辅助工具向"数字同事"的转变,体现在其能根据用户历史沟通风格调整回复语气,并在游戏编程等创意领域提供架构建议。
谷歌战略定位明确拒绝情感陪伴赛道,将模型核心价值聚焦于生产力提升。团队强调,内部考核指标聚焦任务完成量而非用户粘性。这种定位体现在产品设计中——美国大学生将获得一年免费高级权限,模型主打"学习任何事物"的个性化教育场景。
针对行业关注的规模效应争议,开发团队认为当前性能提升仍远超边际成本。尽管回报增速较早期放缓,但在抵达通用人工智能所需的1至2次关键突破前,持续扩大基础模型规模仍是最有效路径。谷歌特有的全栈优势——从定制化TPU芯片到数十亿用户产品矩阵,构成其他竞品难以复制的竞争壁垒。
在图像处理等娱乐场景中,模型延续了技术领先优势。用户可通过自拍生成任意风格的创意照片,或将家庭合影转化为历史场景重现。这种能力不仅适用于节日聚会等社交场景,更能快速生成定制化食谱计算器等实用工具,展现技术落地的多样性。