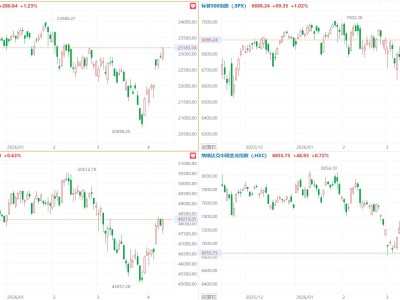
科技领域近期传出重磅消息,英伟达正酝酿一项大胆计划,意图在2028年推出的新一代GPU产品中集成创新技术,以巩固其在AI推理市场的领先地位。这款代号为“费曼”(Feynman)的GPU,将首次尝试融合Groq公司的LPU(语言处理单元)架构,引发行业高度关注。
命名灵感源自诺贝尔物理学奖得主理查德·费曼的这款GPU,其设计理念借鉴了AMD在X3D处理器上的成功经验。行业专家AGF通过技术分析指出,英伟达极有可能采用台积电最先进的SoIC混合键合技术,通过3D堆叠实现芯片架构的重大突破。这种设计将计算核心与存储单元分离制造,再通过垂直堆叠实现高效互联。
具体实现方案显示,主计算模块将采用台积电1.6nm制程的A16工艺制造,集成Tensor计算单元与控制逻辑。而包含大规模SRAM存储阵列的LPU模块则会单独制造成独立芯片,直接堆叠在计算核心上方。这种设计充分利用了A16工艺的背面供电特性,通过释放正面空间实现超低延迟的数据传输通道,理论上可带来显著的性能提升。
推动这种复杂架构设计的核心动因,源于半导体物理层面的现实约束。随着制程工艺向原子级迈进,SRAM存储单元的缩放速度已明显落后于逻辑电路。若在先进制程节点上集成大容量SRAM,不仅会造成高端硅片的浪费,更会导致晶圆成本呈指数级增长。将存储单元剥离为独立芯片进行堆叠,成为平衡性能与成本的最优技术路径,这也与当前芯片行业盛行的“芯粒”(Chiplet)化趋势不谋而合。
尽管3D堆叠方案在理论层面具有显著优势,但其工程实现仍面临多重挑战。首当其冲的是散热问题,在原本高密度的计算核心上叠加存储芯片,极易突破热功耗极限。更棘手的是软件生态适配难题:Groq的LPU架构强调确定性执行流程,而英伟达现有的CUDA生态则建立在硬件抽象与灵活调度基础之上。如何在保持CUDA兼容性的同时,实现两种异构架构的无缝协同,将成为考验英伟达工程团队的关键课题。
这项技术革新若能成功落地,不仅将重新定义AI推理芯片的性能标准,更可能引发整个半导体行业的架构革命。但从业界反馈来看,从实验室原型到商业化产品仍需跨越散热设计、信号完整性、制造良率等多重技术门槛。这场由行业巨头主导的技术博弈,正在为全球AI硬件发展开辟新的可能性空间。