
在2026 GTC大会上,理想汽车正式推出下一代自动驾驶系统核心模型——MindVLA-o1。这款突破性模型通过整合空间感知、逻辑推理与驾驶决策能力,首次实现了对三维物理世界的完整解析,并创新性地将自动驾驶定位为物理人工智能(Physical AI)的起点。其最大亮点在于采用同一套视觉-语言-动作(VLA)架构,可同时操控智能汽车与机器人两种智能体,为跨场景智能应用开辟新路径。
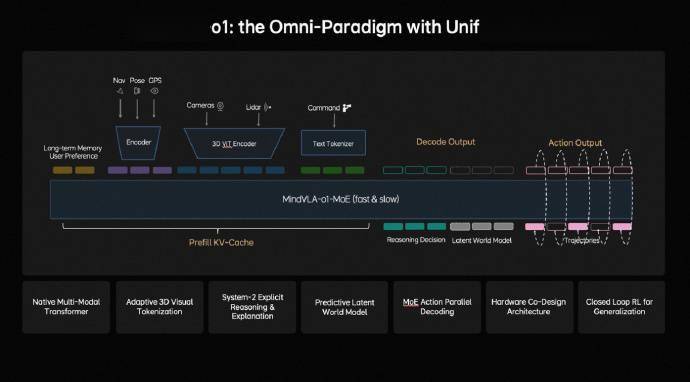
针对传统自动驾驶方案的固有缺陷,研发团队构建了原生3D视觉转换器(ViT)架构。相较于传统BEV方案将三维场景压缩为二维俯视图导致的垂直信息丢失,以及OCC占用网络因缺乏语义理解而无法判断物体可碰撞性的问题,新模型通过多帧视频流直接重建三维空间坐标系。该系统在训练阶段融合了激光雷达的毫米级几何精度与摄像头的语义丰富性,配合前馈式三维高斯溅射(3DGS)技术,可对动态交通参与者与静态道路设施进行独立建模,并通过自监督学习预测未来3-5秒的场景演变,为决策系统提供高保真环境表征。
支撑这一复杂系统运行的是理想自研的马赫100车规级芯片。该芯片在标准矩阵运算任务中展现出较前代产品300%的性能提升,其专用神经网络加速单元可高效处理三维空间重建、多模态融合等密集计算任务,为模型实时运行提供算力保障。特别设计的异构计算架构,使得视觉处理、语言推理与动作规划三大模块可并行运作,将端到端决策延迟控制在80毫秒以内。
在决策层面,MindVLA-o1引入双轨推理机制:System-1系统负责快速响应常规驾驶场景,而System-2系统则通过显式逻辑链构建处理复杂路况。其预测式隐空间模型可模拟超过1000种潜在未来场景,结合强化学习框架生成的驾驶策略库,使系统在面对突发状况时的决策合理性提升47%。测试数据显示,该模型在城区NOA场景下的接管频率较现有系统降低62%,在极端天气条件下的感知距离扩展至280米。
理想汽车同步构建的具身智能开发平台,实现了从数据采集到模型部署的全链条革新。统一数据引擎可自动标注来自真实道路与数字孪生环境的多元数据,仿真系统支持每秒生成200个高保真驾驶场景,配合分布式强化学习框架,使模型训练效率提升8倍。这种模块化设计使得MindVLA-o1既能快速适配不同车型,也可通过参数微调扩展至工业搬运、服务机器人等非交通领域。










