近日,阿里巴巴在文本处理领域迈出了重要一步,正式推出了Qwen3-Embedding和Qwen3-Reranker系列模型。这两项技术的发布,不仅伴随着详尽的技术报告,还首次公开了模型的推理架构、训练策略以及评测结果,并宣布开源供开发者免费使用。
Qwen3-Embedding和Qwen3-Reranker均基于Qwen3基础模型进行训练,专为文本表征、检索与排序任务打造。其中,Qwen3-Embedding能够接收单段文本,并将其转换为语义向量,适用于语义搜索、问答系统等场景。而Qwen3-Reranker则接收文本对,通过单塔结构计算并输出两个文本的相关性得分,有效提升各类文本检索场景中搜索结果的相关性。
在实际应用中,Qwen3-Embedding和Qwen3-Reranker往往结合使用。例如,在RAG系统中,Qwen3-Embedding负责初步检索,Qwen3-Reranker则负责优化候选结果,从而在效率和精度上达到平衡。
Qwen3-Embedding 8B版本在MTEB(文本嵌入模型评测基准)多语言榜上取得了70.58分的高分,荣登榜首,创造了历史新高。同时,Qwen3-Reranker在mMARCO跨语言检索中的MRR@10指标达到了0.42,超越了行业标杆。这两个模型均支持119种语言及编程语言,提供0.6B、4B、8B三种参数规模,其中Reranker对100文档排序的延迟控制在了80ms以内(A100),且长文本处理能力突破了32k上下文。
阿里巴巴此次开源的Qwen3-Embedding和Qwen3-Reranker模型,在Hugging Face、GitHub和ModelScope平台上均可免费获取,并且阿里云API也同步上线,方便开发者一键部署。
Qwen3-Embedding模型在权威评测中表现卓越,不仅在MTEB多语言Leaderboard榜单中位列第一,超越了包括Google Gemini-Embedding在内的商业模型,还在代码检索任务中搜索精准度排名第一。在多模态文本嵌入(MTEB)跨语言场景下,Qwen3-Embedding 8B模型也取得了令人瞩目的成绩。
Qwen3-Embedding模型的成功,得益于其创新的双编码器架构和深度语言理解能力。该模型采用三阶段训练框架,通过弱监督预训练、监督微调和模型融合技术,提升了模型的泛化性。同时,Qwen3-Embedding模型还支持自定义指令模板,使得特定任务性能能够提升3%-5%。
而Qwen3-Reranker模型则专为提升搜索和推荐系统相关性排序能力而设计。其采用的单塔交互结构,能够动态计算查询-文档交互特征,输出相关性得分,实现实时排序。针对长文档场景,Qwen3-Reranker模型还集成了RoPE位置编码与双块注意机制,有效避免了长程信息丢失,确保了32k上下文内的语义连贯性。
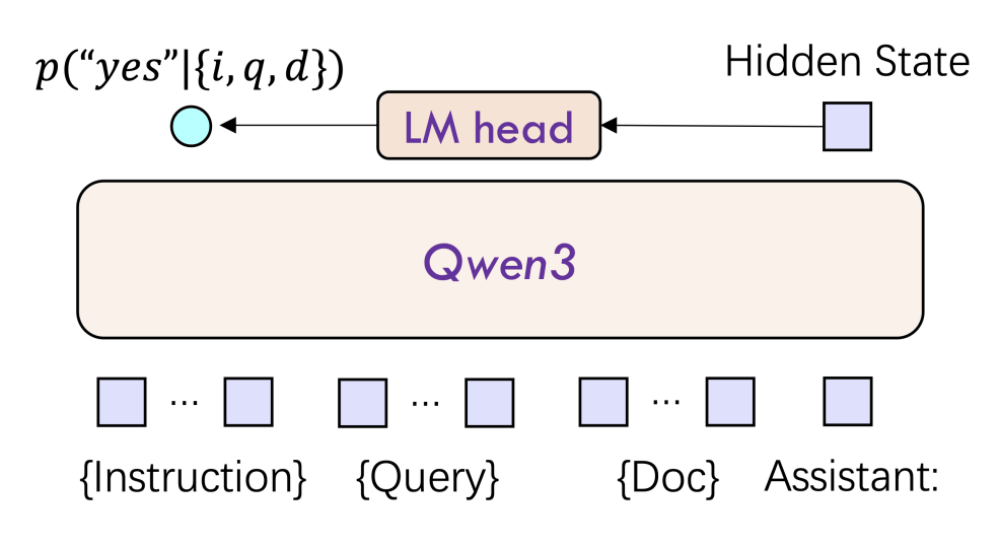
Qwen3-Reranker系列模型同样提供0.6B、4B、8B三种参数规模,以满足不同场景下的性能与效率需求。其中,Qwen3-Reranker 8B模型在多语言检索任务中取得了69.02分的高分,显著优于传统BM25和ColBERT等其他基线模型。Qwen3-Reranker模型还支持任务指令微调,开发者可通过自定义指令优化特定领域性能。
阿里巴巴的开源策略,无疑将加速文本检索技术的普及和创新。开发者可以基于Hugging Face平台快速微调模型,企业也可以通过阿里云API即时部署。这一举措不仅降低了技术门槛,还推动了文本检索从“关键词匹配”向“语义理解+动态交互”的升级,为AI Agent和多模态应用的发展奠定了基础。
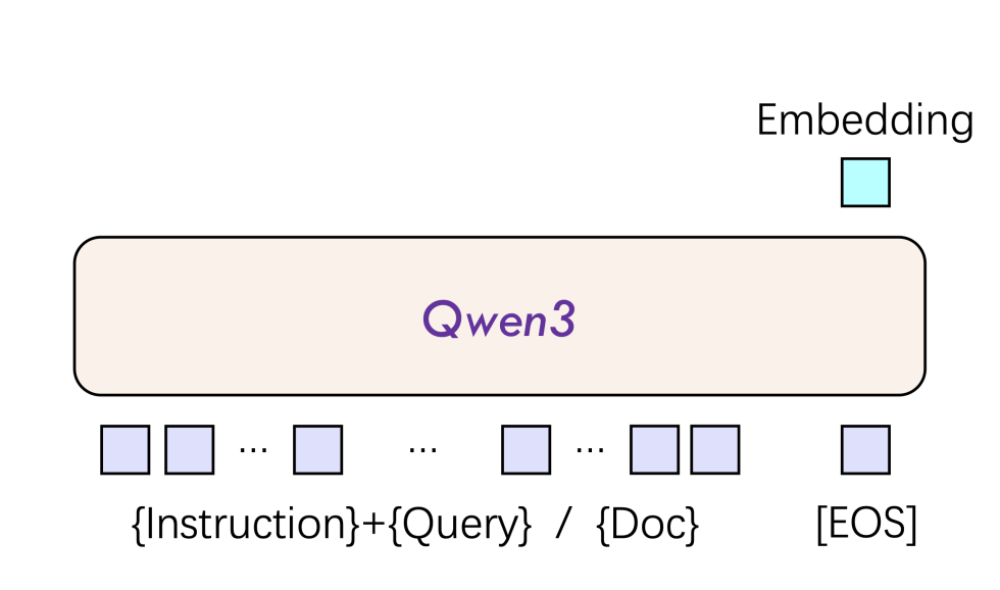
Qwen3-Embedding和Qwen3-Reranker模型的发布,也反映出AI模型正从“通用泛化”向“精准专用”演进。在实际检索场景中,应用者需要根据具体任务、语言和场景设计指令模板,以达到最佳效果。这一细节为行业提供了新的优化思路,也预示着文本处理技术将进入更加精准和专用的时代。