近期,科技界迎来了一项重大突破,meta公司推出了名为LlamaRL的创新框架,这一框架专为强化学习在大语言模型中的应用而设计。据科技媒体marktechpost于6月10日的报道,LlamaRL采用了全异步分布式设计,极大地提升了训练效率。
强化学习,作为一种通过反馈调整输出以更贴合用户需求的算法,近年来在先进大语言模型系统中扮演着愈发重要的角色。然而,将强化学习应用于大语言模型的最大挑战在于其庞大的资源需求。训练过程中涉及的海量计算和多组件协调,如策略模型、奖励评分器等,使得这一过程极为复杂且耗时。
meta的LlamaRL框架正是为了解决这些问题而生。它基于PyTorch构建,采用了全异步分布式系统,这一设计不仅简化了组件之间的协调,还支持模块化定制,使得工程师能够更灵活地调整和优化模型。通过独立执行器并行处理生成、训练和奖励模型,LlamaRL显著减少了等待时间,从而提升了整体训练效率。
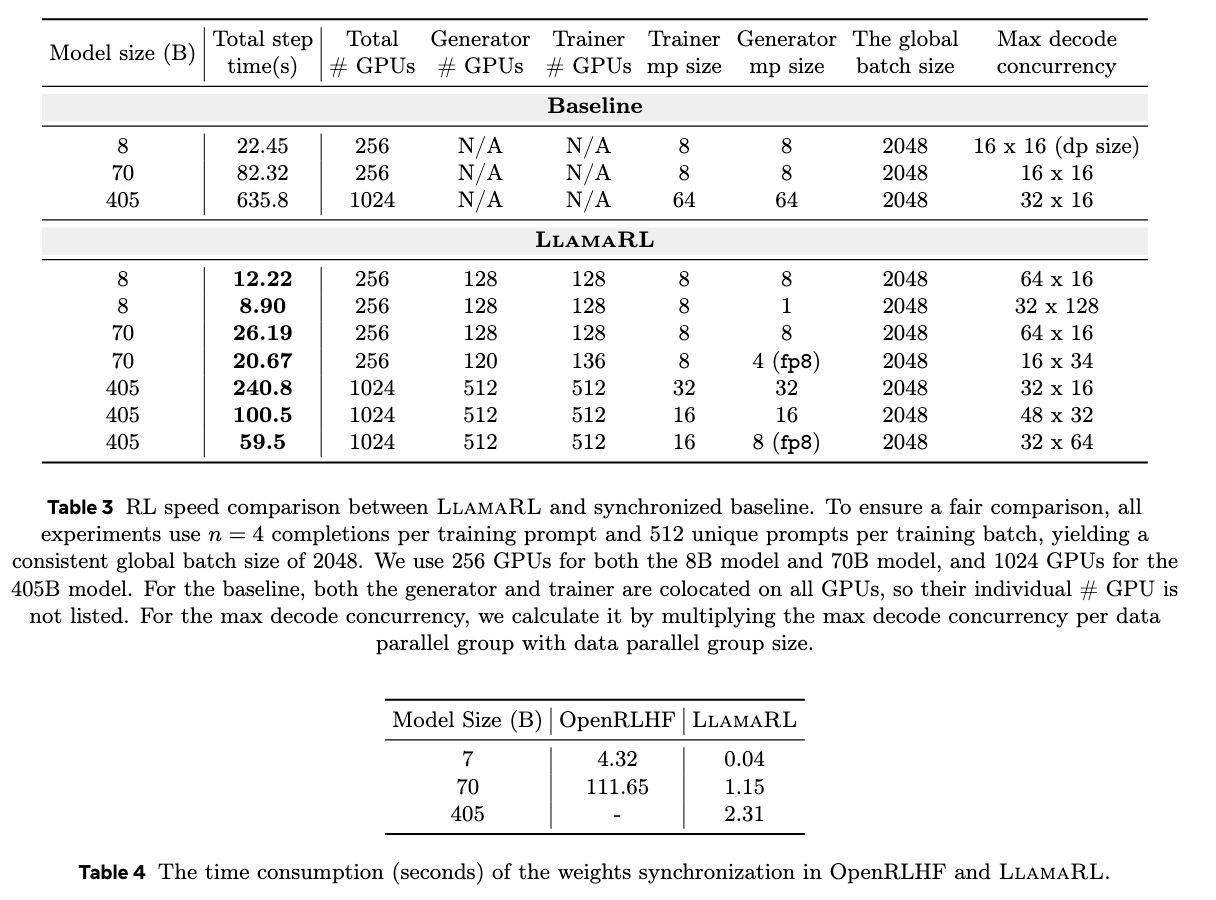
更LlamaRL框架还利用了分布式直接内存访问(DDMA)和NVIDIA NVLink技术,实现了模型权重的快速同步。在405B参数模型上,权重同步仅需2秒,这一速度的提升无疑为大规模模型的训练带来了极大的便利。
在实际测试中,LlamaRL的表现令人瞩目。在8B、70B和405B模型上,它将训练时间分别缩短至8.90秒、20.67秒和59.5秒,速度提升最高达到了10.7倍。这一成绩不仅证明了LlamaRL框架的高效性,也为其在大语言模型训练中的应用奠定了坚实的基础。
LlamaRL在性能方面也表现出色。在MATH和GSM8K基准测试中,其性能稳定甚至略有提升。这一结果不仅验证了LlamaRL框架的有效性,也展示了它在解决内存限制和GPU效率问题方面的卓越能力。可以说,LlamaRL为训练大语言模型开辟了一条可扩展的新路径。