百度于6月30日正式宣布,文心大模型4.5系列全面开源。此次开源涵盖了多款模型,包括具备47B和3B激活参数的混合专家(MoE)模型,以及拥有0.3B参数的稠密型模型等,总计达10款。这些模型的预训练权重与推理代码均已实现完全开放,为开发者提供了丰富的资源。
文心大模型4.5系列现已在飞桨星河社区、HuggingFace等平台上线,开发者可以方便地下载并部署这些模型。同时,百度智能云千帆大模型平台也提供了开源模型的API服务,进一步拓宽了模型的应用场景。
早在今年2月,百度便预告了文心大模型4.5系列的即将推出,并确定了6月30日的开源日期。此次开源的模型在多个关键维度上均处于行业领先地位,包括独立自研模型的数量占比、模型类型的多样性、参数的丰富程度,以及开源的宽松度和可靠性。
文心大模型4.5系列在MoE架构上进行了创新,提出了一种多模态异构模型结构。这种结构适用于从大语言模型向多模态模型的持续预训练,能够在保持或提升文本任务性能的同时,显著增强多模态理解能力。这一优越性能得益于多模态混合专家模型的预训练技术、高效的训练推理框架,以及针对模态的后训练技术。
该系列模型均使用飞桨深度学习框架进行训练和推理,效率显著提升。在大语言模型的预训练中,模型的FLOPs利用率达到了47%。实验结果显示,文心大模型4.5系列在多个文本和多模态基准测试中均达到了业界领先水平,特别是在指令遵循、世界知识记忆、视觉理解和多模态推理等任务上表现突出。
在文本模型方面,文心大模型4.5系列展现出了强大的基础能力、高准确性的事实理解、出色的指令遵循能力,以及卓越的推理和编程能力。在多个主流基准评测中,该系列模型超越了DeepSeek-V3、Qwen3等模型。而在多模态模型方面,文心大模型4.5系列则拥有卓越的视觉感知能力和丰富的视觉常识,实现了思考与非思考的统一。在视觉常识、多模态推理、视觉感知等主流的多模态大模型评测中,该系列模型优于闭源的OpenAI模型。
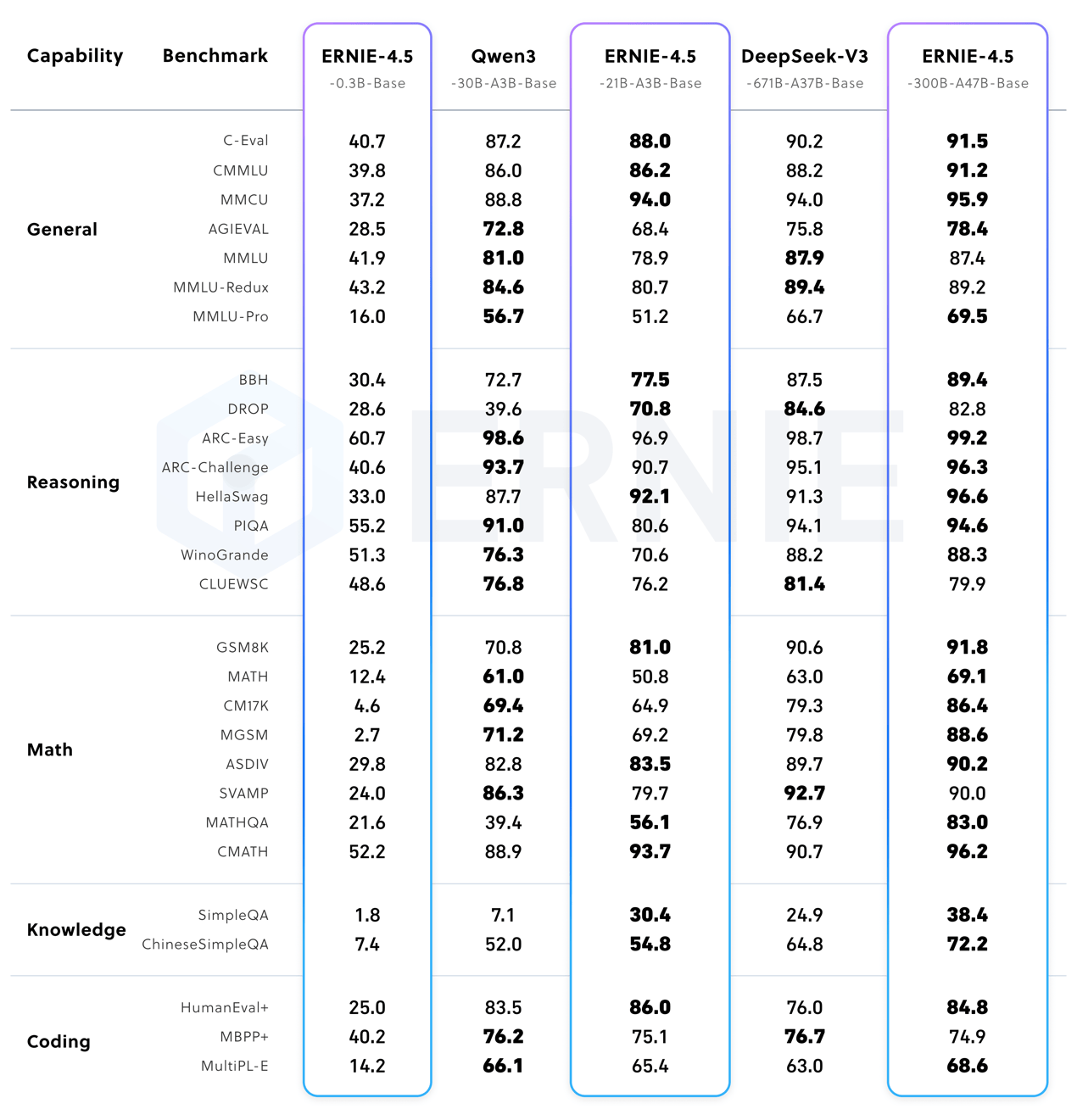
文心4.5-21B-A3B-Base文本模型的效果与同量级的Qwen3相当,而文心4.5-VL-28B-A3B多模态模型则是目前同量级中最好的多模态开源模型,其性能甚至与更大参数的Qwen2.5-VL-32B模型不相上下。
文心大模型4.5系列的权重按照Apache 2.0协议进行开源,支持学术研究和产业应用。同时,基于飞桨提供的开源产业级开发套件,该系列模型能够广泛兼容多种芯片,降低了模型的后训练和部署门槛。
作为国内AI研发的先行者,百度在算力、框架、模型到应用的全链条布局上构建了显著的AI技术优势。飞桨作为中国首个自主研发、功能全面的开源深度学习平台,基于多年的技术和生态系统积累,此次同步升级发布了文心大模型开发套件ERNIEKit和大模型高效部署套件FastDeploy。这些工具为文心大模型4.5系列及开发者提供了即插即用的全流程支持。
值得注意的是,文心大模型4.5系列的开源标志着百度在框架层与模型层实现了“双层开源”,为行业树立了新的标杆。