讯 7月4日,阿里通义实验室宣布开源首个音频生成模型ThinkSound。该模型首次将思维链(CoT)技术应用于音频生成领域,旨在解决现有视频转音频(V2A)技术对画面动态细节和事件逻辑理解不足的问题。
根据通义语音团队介绍,传统V2A技术常难以精确捕捉视觉与声音的时空关联,导致生成音频与画面关键事件错位。ThinkSound通过引入结构化推理机制,模仿人类音效师的分析过程:首先理解视频整体画面与场景语义,再聚焦具体声源对象,最后响应用户编辑指令,逐步生成高保真且同步的音频。
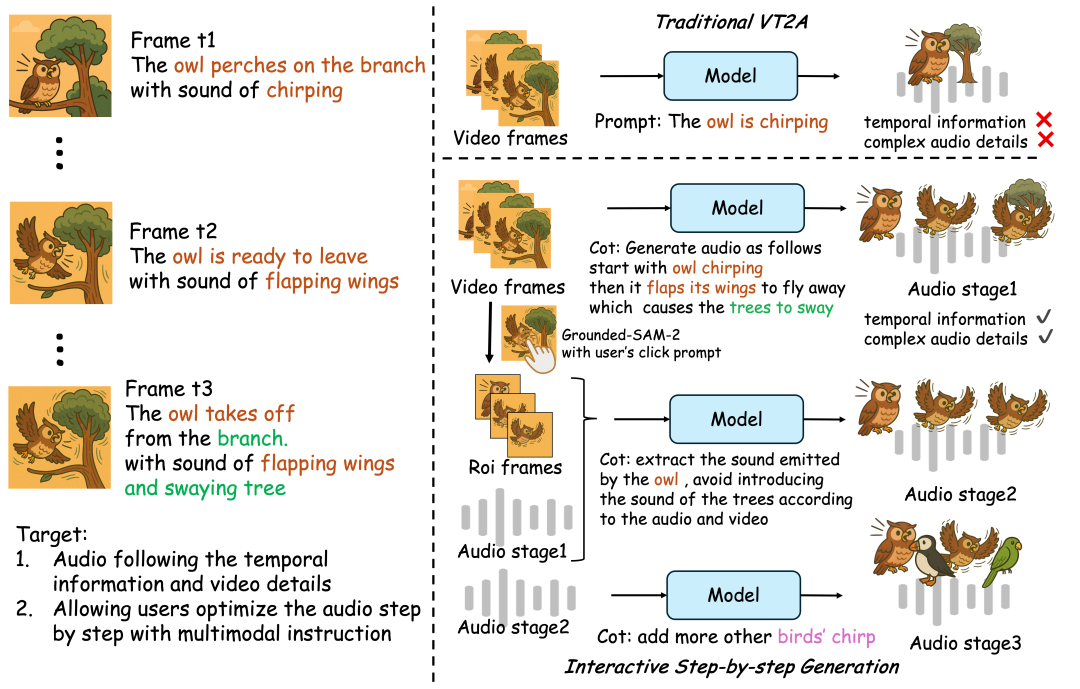
图源:通义大模型微信公众号
为训练模型,团队构建了首个支持链式推理的多模态音频数据集AudioCoT,包含超2531小时高质量样本,覆盖丰富场景,并设计了面向交互编辑的对象级和指令级数据。ThinkSound由一个多模态大语言模型(负责“思考”推理链)和一个统一音频生成模型(负责“输出”声音)组成。
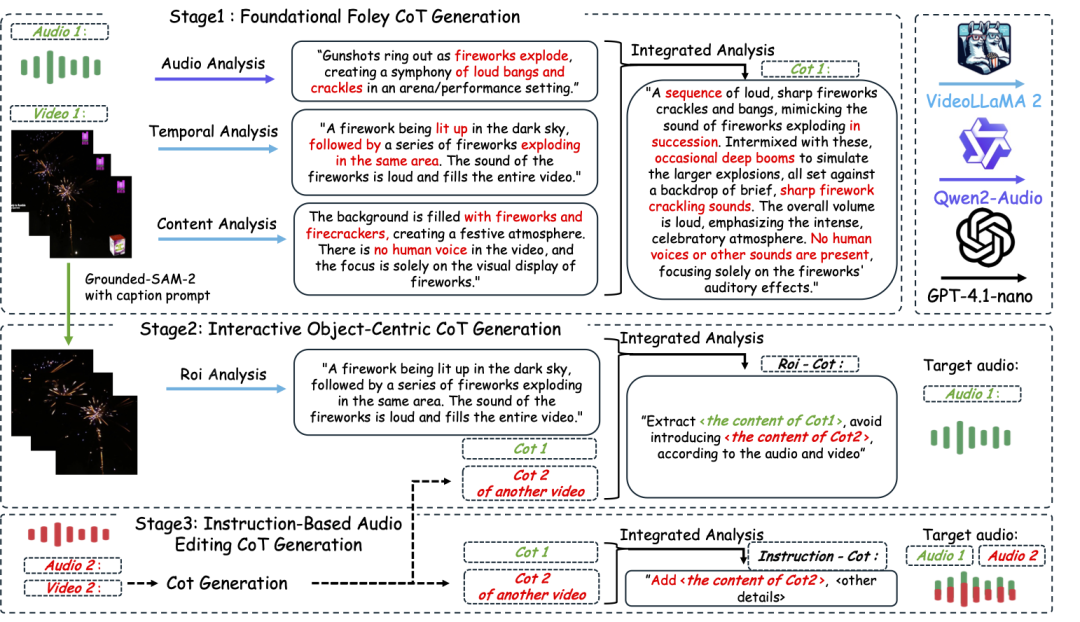
ThinkSound 音频生成模型的工作流
据悉,ThinkSound在多项权威测试中表现优于现有主流方法。该模型现已开源,开发者可在GitHub、Hugging Face、魔搭社区获取代码和模型。未来将拓展其在游戏、VR/AR等沉浸式场景的应用。
以下附上开源地址:
https://github.com/FunAudioLLM/ThinkSound
https://huggingface.co/spaces/FunAudioLLM/ThinkSound
https://www.modelscope.cn/studios/iic/ThinkSound