百度近日宣布,文心大模型4.5系列正式面向公众开源,此次开源涵盖了多款模型,其中包括拥有47B和3B激活参数的混合专家(MoE)模型,以及参数量为0.3B的稠密型模型等,总计达到10款。值得注意的是,百度不仅公开了这些模型的预训练权重,还提供了推理代码,实现了完全的开源。
文心大模型4.5系列现已在多个平台上架,用户可以在飞桨星河社区、HuggingFace等平台下载并部署这些模型。同时,百度智能云千帆大模型平台也提供了相应的开源模型API服务,进一步降低了使用门槛。
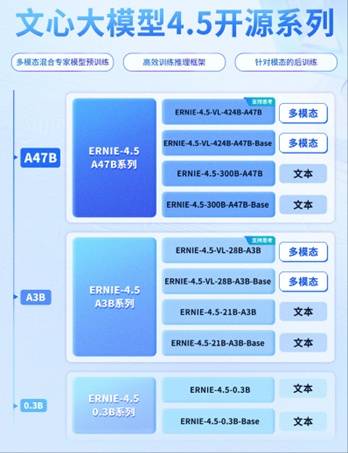
百度此次开源的文心大模型4.5系列,在多个关键维度上均展现出了行业领先的优势。无论是独立自研的模型数量占比,还是模型类型的多样性、参数的丰富程度,以及开源的宽松度和可靠性,百度都交出了亮眼的成绩单。
文心大模型4.5系列在MoE架构上进行了创新,提出了一种全新的多模态异构模型结构。这种结构不仅适用于从大语言模型向多模态模型的持续预训练,还在保持或提升文本任务性能的同时,显著增强了模型的多模态理解能力。文心大模型4.5系列的权重按照Apache 2.0协议进行开源,为学术研究和产业应用提供了有力支持。
基于飞桨这一中国首个自主研发、功能丰富的产业级深度平台,百度此次还同步发布了文心大模型开发套件ERNIEKit和大模型高效部署套件FastDeploy。这两个套件为文心大模型4.5系列及开发者提供了从开发到部署的全流程支持,大大降低了模型的后训练和部署难度。同时,飞桨的广泛兼容性也使得这些模型能够在多种芯片上运行,进一步拓宽了应用场景。
此次文心大模型4.5系列的开源,标志着百度在框架层和模型层都实现了开源。这一举措不仅展示了百度在人工智能领域的深厚积累,也为行业内外提供了宝贵的技术资源和创新动力。